2 Introducción a la ciencia de datos
Trabajo previo
Lecturas
Çetinkaya-Rundel, Mine, & Hardin, Johanna (2021). Chapter 1: Hello data en Introduction to Modern Statistics (1st ed.). OpenIntro, Inc. https://openintro-ims.netlify.app/data-hello
Singleton, Alex David; Spielman, Seth; & Brunsdon, Chris (2016). Establishing a framework for Open Geographic Information science. International Journal of Geographical Information Science, 30(8), 1507-1521. https://doi.org/10.1080/13658816.2015.1137579
Wickham, Hadley; Çetinkaya-Rundel, Mirne; & Grolemund, Garret (2023). Introduction en R for Data Science: Import, Tidy, Transform, Visualize, and Model Data (2nd ed.). O’Reilly Media. https://r4ds.hadley.nz/intro
Introducción
Una investigación estadística se basa en datos. Los datos acostumbran representarse en tablas, en las cuales cada fila es una observación y cada columna es una variable. Una observación corresponde a un elemento de datos que ha sido estudiado y cada variable a una característica de ese elemento. Las variables pueden ser numéricas o categóricas. Las numéricas se subdividen en discretas y continuas y las categóricas en nominales y ordinales.
La ciencia de datos es una disciplina que permite convertir datos sin procesar en comprensión y conocimiento. El ciclo de vida de un proyecto de ciencia de datos incluye los procesos importar, ordenar, transformar, visualizar, modelar y comunicar. La programación de computadoras puede emplearse en cualquier etapa del ciclo de vida de un proyecto para automatizar tareas y a resolver nuevos problemas con mayor facilidad.
El surgimiento de la ciencia de datos está motivado por un incremento acelerado de la cantidad de datos existentes, así como de la disponibilidad de herramientas computacionales y de infraestructura informática para procesarlos y analizarlos. Estos cambios tecnológicos han sido apoyados por un cambio cultural propiciado por movimientos como el de ciencia abierta (open science), el cual promueve el acceso libre a la investigación científica, incluidas las publicaciones, los datos, las metodologías y el código fuente.
Un aspecto crucial de la ciencia abierta es la reproducibilidad, que garantiza que los resultados de una investigación puedan ser verificados y validados por otros investigadores. Hay varias herramientas que pueden facilitar la reproducibilidad en ciencia de datos, incluyendo lenguajes de programación, lenguajes de marcado y sistemas de control de versiones.
2.1 Datos
Los científicos tratan de responder preguntas mediante métodos rigurosos y observaciones cuidadosas. Estas observaciones, recopiladas de notas de campo, encuestas y experimentos, entre otras fuentes, forman la columna vertebral de una investigación estadística y se denominan datos. La presentación y descripción efectivas de los datos constituyen el primer paso en un análisis Çetinkaya-Rundel & Hardin (2021). Esta sección introduce una estructura para organizar los datos, así como alguna terminología que se utilizará a lo largo de este curso.
2.1.1 Observaciones y variables
La tabla 1 contiene 10 filas de un conjunto de datos. Cada fila representa una persona. En términos estadísticos, cada fila corresponde a una observación. Las columnas representan características de las personas. Cada columna corresponde a una variable.
| cedula | provincia | equipo | peso | estatura | sexo | cantidad_hermanos | nivel_guitarra |
|---|---|---|---|---|---|---|---|
| 709880238 | Limón | Saprissa | 51.0 | 1.51 | desconocido | 0 | nulo |
| 400680168 | Heredia | Herediano | 98.5 | 1.87 | hombre | 1 | alto |
| 509210285 | Guanacaste | Liberia | 91.6 | 1.65 | mujer | 4 | bajo |
| 701950272 | Limón | Liberia | 60.6 | 1.68 | mujer | 1 | alto |
| 309880238 | Cartago | Cartaginés | 59.1 | 1.73 | mujer | 3 | bajo |
| 908280708 | Desconocida | San Carlos | 59.2 | 1.89 | hombre | 3 | bajo |
| 505580938 | Guanacaste | Cartaginés | 65.2 | 1.70 | mujer | 3 | alto |
| 504080488 | Guanacaste | Sporting | 76.2 | 1.76 | hombre | 3 | experto |
| 709950244 | Limón | Alajuelense | 71.6 | 1.80 | hombre | 4 | bajo |
| 206080825 | Alajuela | Alajuelense | 64.6 | 1.52 | hombre | 2 | bajo |
2.1.2 Tipos de variables
Las variables de los datos de la tabla 1 son de varios tipos, cuya jerarquía se muestra en la Figura 2.1.
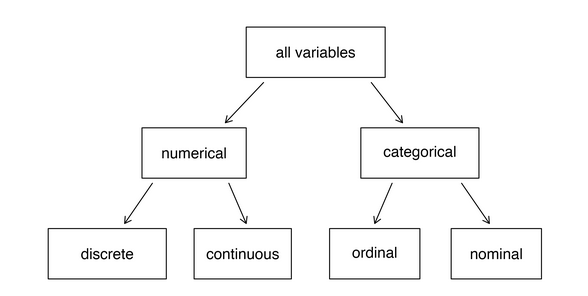
Seguidamente, se describen estos tipos de datos de las variables.
2.1.2.1 Numéricas
Corresponden a números a los cuales se les pueden aplicar operaciones como suma, resta, multiplicación, división y otras similares. Las variables numéricas puden ser discretas o continuas.
2.1.2.1.1 Discretas
Toman valores específicos que se pueden contar. La variable cantidad_hermanos es discreta. Existe una separación clara entre sus posibles valores. Por ejemplo, es posible tener 1, 2 o 3 hermanos, pero no 2.5.
2.1.2.1.2 Continuas
Pueden tomar cualquier valor dentro de un intervalo o rango continuo. Estas variables se caracterizan por su capacidad para representar medidas precisas y pueden asumir un número infinito de valores, incluso dentro de un rango limitado (ej. entre 0 y 1). Las variables peso y estatura son continuas.
2.1.2.2 Categóricas
Las variables categóricas (también llamadas cualitativas), son aquellas que describen una característica o cualidad de una observación y pueden utilizarse para clasificar las observaciones en grupos o categorías. A diferencia de las variables numéricas, que expresan cantidades, las variables categóricas expresan atributos no numéricos. Las variables categóricas pueden ser nominales u ordinales.
2.1.2.2.1 Nominales
No existe un orden inherente o jerarquía entre las categorías. Las variables provincia, equipo y sexo son nominales.
2.1.2.2.2 Ordinales
Hay un orden o jerarquía clara entre las categorías. La variable nivel_guitarra, con sus valores nulo, bajo, alto y experto, es ordinal.
2.2 Ciclo de vida de un proyecto de ciencia de datos
La ciencia de datos es una disciplina que permite convertir datos “crudos” (sin procesar) en comprensión y conocimiento Wickham, Çetinkaya-Rundel, & Grolemund (2023). Se basa en la estadística y en las ciencias de la computación, entre otras disciplinas.
2.2.1 Procesos
La Figura 7.1 ilustra el ciclo de vida de un proyecto típico de ciencia de datos, el cual incluye los procesos de importar, ordenar, transformar, visualizar, modelar y comunicar. Todos se articulan mediante programación de computadoras.

2.2.1.1 Importar
Importar los datos generalmente implica leerlos de un archivo, una base de datos o una interfaz de programación de aplicaciones (API) y cargarlos en estructuras apropiadas para este propósito en un lenguaje de programación.
2.2.1.2 Ordenar
Ordenar o estructurar (to tidy) los datos significa colocarlos en estructuras rectangulares de filas y columnas, similares a tablas, de manera que cada fila sea una observación y cada columna una variable. En algunos casos, pueden requerirse estructuras de otros tipos.
2.2.1.3 Transformar
Transformar los datos incluye, entre otras operaciones, la generación de algún subconjunto de observaciones o variables del conjunto original, la creación de nuevas variables a partir de las ya existentes o el cálculo de estadísticas como conteos y promedios.
Una vez que los datos están bien estructurados y con las variables que se requieren para el análisis, se puede proceder a la generación de conocimiento mediante dos mecanismos: la visualización y la modelización. Ambos tienen fortalezas y debilidades y es común iterar varias veces entre uno y otro.
2.2.1.4 Visualizar
Visualizar los datos en tablas, gráficos, mapas u otros formatos permite encontrar patrones inesperados o formular nuevas preguntas. Una buena visualización también puede indicar si se están formulando preguntas equivocadas o utilizando datos que no son apropiados para el problema que se desea resolver. Es importante tener en cuenta que las visualizaciones deben ser interpretadas por seres humanos. Por este motivo, visualizaciones como gráficos estadísticos y mapas deben ser seleccionadas con cuidado y elaborarse detalladamente.
2.2.1.5 Modelar
Modelar es crear una representación abstracta y estructurada de los datos, con el fin de facilitar su análisis y realizar predicciones. Al ser herramientas matemáticas o computacionales, los modelos muchas veces pueden mejorarse mediante el empleo de mayores capacidades de cómputo, lo que los hace menos dependientes de la intervención humana, como en el caso de las visualizaciones.
2.2.1.6 Comunicar
Comunicar es el último paso y es una actividad crítica de cualquier proyecto de análisis de datos o de ciencia en general. No importa lo bien que los modelos y visualizaciones ayuden a entender los datos si los resultados no pueden ser comunicados a otras personas.
2.2.1.7 Programar
La programación de computadoras se utiliza de manera transversal en los procesos recién descritos. Puede emplearse en cualquier etapa del ciclo de vida de un proyecto de ciencia de datos. Es útil para automatizar tareas y a resolver nuevos problemas con mayor facilidad.
2.2.2 Ejemplos
Las etapas iniciales de un proyecto de ciencia de datos incluyen técnicas estadísticas convencionales como el análisis exploratorio de datos (EDA), mientras que las más avanzadas pueden involucrar técnicas de inteligencia artificial como aprendizaje automático (machine learning) y aprendizaje profundo (deep learning).
La Figura 2.3 ilustra varios problemas resueltos mediante regresión y clasificación, dos técnicas que se utilizan en deep learning. En cada caso, hay una entrada que puede tener diversos formatos como un conjunto de números, una hilera de texto, un archivo de sonido o una imagen. Esta entrada se transforma y se codifica como un vector de números. Este vector constituye la entrada del modelo de regresión o clasificación. El modelo convierte la entrada en un vector de salida que se “traduce” de nuevo a un formato adecuado.
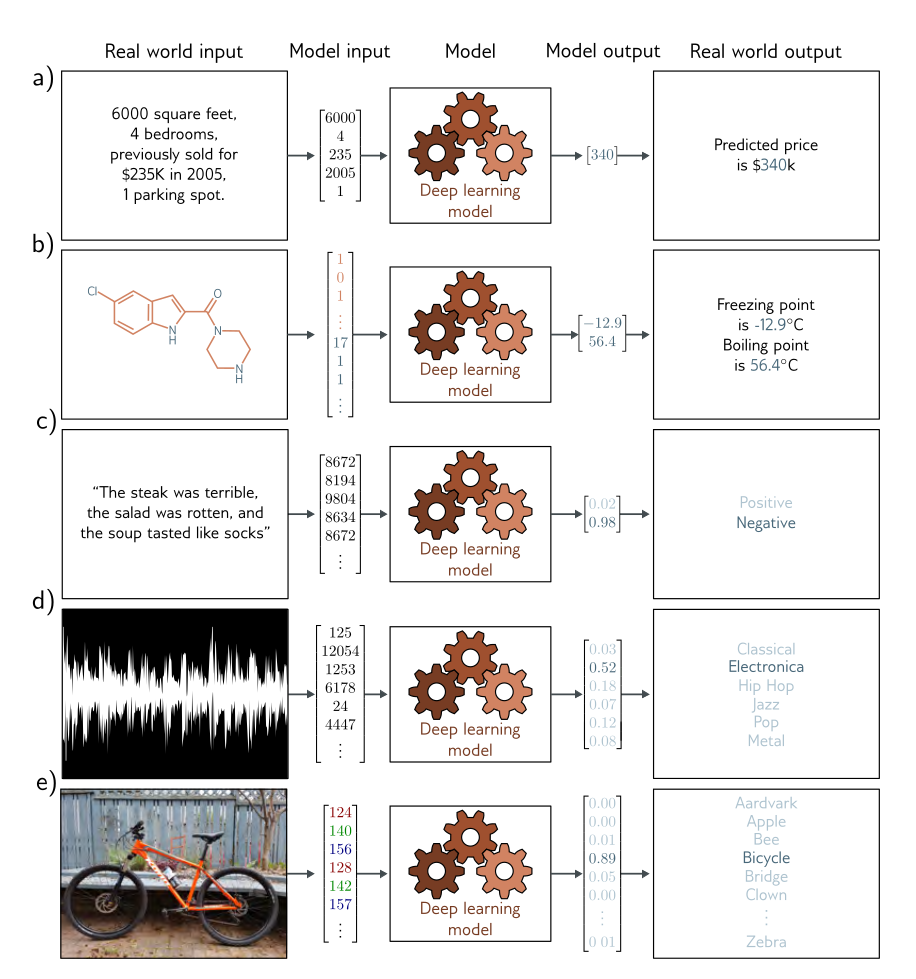
El modelo de a) predice el precio de una vivienda en función de características de entrada como el área en pies cuadrados y el número de dormitorios 1. Se trata de un problema de regresión, ya el modelo retorna un número real (no asigna una categoría). El modelo de la figura b) recibe la estructura química de una molécula como entrada y predice su punto de congelación y su punto de ebullición. Este es un problema de regresión multivariada, ya que la salida incluye más de un número.
El modelo en c) recibe como entrada una hilera de texto que contiene las calificaciones de varios aspectos a evaluar sobre una comida en un restaurante (plato principal, ensalada, sopa, postre, etc.) y predice si el resultado general es positivo o negativo. Es un problema de clasificación binaria porque el modelo asigna como salida una de dos categorías. El vector de salida contiene las probabilidades de posible valor. Los modelos en d) y e) corresponden a problemas de clasificación multiclase. Aquí, el modelo asigna el valor de salida a una de n > 2 categorías. En el primer caso, la entrada es un archivo de audio y el modelo predice el género musical al que pertenece. En el segundo caso, la entrada es una imagen y el modelo predice qué objeto contiene. En cada caso, el modelo devuelve un vector de tamaño n que contiene las probabilidades de las n categorías.
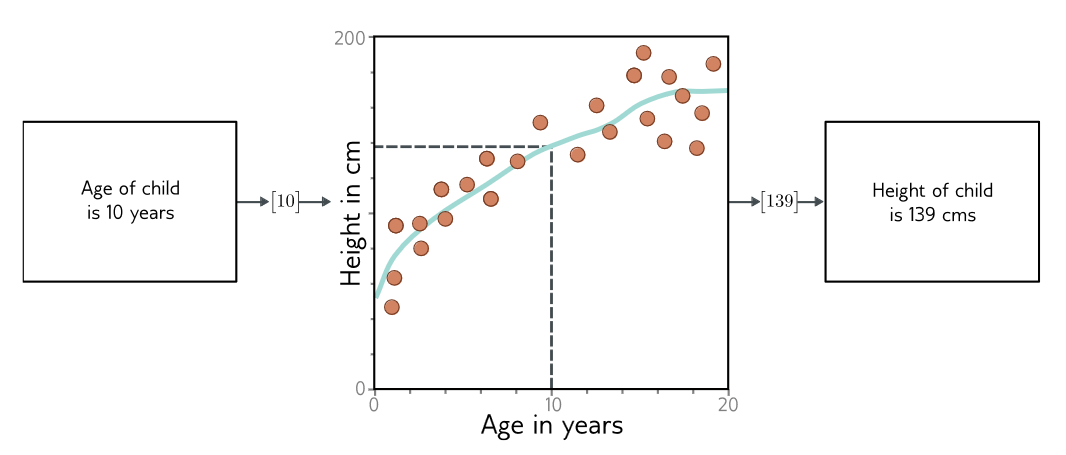
En la Figura 2.3, los modelos de deep learning se muestran como “cajas negras” que reciben una entrada y retornan una salida, sin entrar en detalles de como se procesa la entrada. Hay muchas posibilidades para implementar estas “cajas negras”. Considere un modelo para predecir la estatura de un niño a partir de su edad, como el de la Figura 2.4. En este caso, el modelo es una ecuación que describe como la estatura promedio varía en función de la edad. Al ingresar la edad a la ecuación, retorna la estatura.
El surgimiento de la ciencia de datos está motivado por un incremento acelerado de la cantidad de datos existentes, así como de la disponibilidad de herramientas computacionales (lenguajes de programación, motores de bases de datos) y de infraestructura informática (hospedaje de datos, hospedaje de aplicaciones) para procesarlos y analizarlos. Los cambios tecnológicos han sido apoyados por un cambio cultural propiciado por movimientos como los de código abierto (open source), datos abiertos (open data), acceso abierto (open access) y ciencia abierta (open science). La ciencia abierta, que de alguna manera engloba a los otros movimientos abiertos, promueve el acceso libre a la investigación científica, incluidas las publicaciones, los datos, las metodologías y el código fuente, de manera que sean accesibles a todos los niveles de la sociedad. Un aspecto crucial de la ciencia abierta es la reproducibilidad, que garantiza que los resultados de una investigación puedan ser verificados y validados por otros investigadores.
2.3 Reproducibilidad
La reproducibilidad es la capacidad de un ensayo o experimento de ser reproducido por otros. Más formalmente, en investigación cuantitativa, un análisis se considera reproducible si “el código fuente y los datos utilizados por un investigador para llegar a un resultado están disponibles y son suficientes para que otro investigador, trabajando de manera independiente, pueda llegar al mismo resultado” Gandrud (2020).
La reproducibilidad, junto con la falsabilidad, es uno de los pilares del método científico. Sin embargo, en años recientes, se ha generado una creciente preocupación debido a que muchos estudios científicos publicados fallan las pruebas de reproducibilidad, dando lugar a una crisis de reproducibilidad o replicabilidad en varias ciencias Krugman (2013).
El concepto de reproducibilidad es cada vez más importante debido, entre otras razones, al aumento exponencial de datos disponibles y a la aplicación de la programación de computadoras, para procesar estos datos, por parte de especialistas de muchas disciplinas.
Alex Singleton y otros autores han identificado los siguientes retos para la reproducibilidad en ciencia de datos geoespaciales Singleton, Spielman, & Brunsdon (2016):
- Los datos deben ser de dominio público y estar disponibles para los investigadores.
- El software utilizado debe ser de código abierto (open source) y estar disponible para ser revisado.
- Siempre que sea posible, los flujos de trabajo deben ser públicos y con enlaces a los datos, software y métodos de análisis, junto con la documentación necesaria.
- El proceso de revisión por pares (peer review process) y la publicación académica deben requerir la presentación de un modelo de flujo de trabajo e idealmente la disponibilidad de los materiales necesarios para la replicación.
- En los casos en los que la reproducibilidad total no sea posible (ej. datos sensibles), los investigadores deben esforzarse por incluir todos los aspectos que puedan de un marco de trabajo abierto.
En general, el estándar mínimo de reproducibilidad requiere que los datos y el código fuente estén disponibles para otros investigadores Peng (2011). Sin embargo, dependiendo de las circunstancias y recursos disponibles, existe todo un espectro de posibilidades, que se ilustra en la Figura 2.5.

2.4 Herramientas para ciencia de datos
Como se ha mencionado, la programación de computadoras es una actividad presente durante todos los procesos de ciencia de datos. Hay muchos lenguajes que pueden utilizarse en este campo. Entre los más populares, pueden mencionarse Python, R, SQL y JavaScript.
Por otra parte, la documentación es vital durante todo el ciclo de vida de una investigación reproducible. Se recomienda utilizar mecanismos estandarizados y abiertos como el lenguaje de marcado de hipertexto (HTML, en inglés, HyperText Markup Language) o Markdown, con los cuales pueden crearse documentos mediante editores de texto simples (i.e. no se requiere de software propietario), y exportables a varios formatos (ej. LaTeX, PDF).
Para dar mantenimiento, tanto al código fuente como a la documentación, es necesario un sistema de control de versiones como Git, el cual permite llevar el registro de los cambios en archivos y también facilita el trabajo colaborativo al reunir las modificaciones hechas por varias personas. Git es usado en varias plataformas que comparten código fuente (ej. GitHub, GitLab) y que ofrecen servicios relacionados, como hospedaje de sitios web.
2.5 Referencias bibliográficas
Como ejemplo, puede revisar el problema de la estimación de precios de viviendas en Boston en Harrison & Rubinfeld (1978) (el texto completo está en https://deepblue.lib.umich.edu/bitstream/handle/2027.42/22636/0000186.pdf) y acceder a los datos correspondientes en Kaggle.↩︎