# Instalación de todos los paquetes de Tidyverse (opcional).
# Si se hace, no es necesario instalar ggplot2 y readr por separado.
install.packages("tidyverse")
# Instalación de ggplot2
install.packages("ggplot2")
# Instalación de readr
install.packages("readr")
# Instalación de plotly
install.packages("plotly")
# Instalación de DT
install.packages("DT")9 ggplot2 y plotly - creación declarativa de gráficos interactivos
9.1 Trabajo previo
9.1.1 Lecturas
Chang, W. (2018). R graphics cookbook: Practical recipes for visualizing data. O’Reilly. https://r-graphics.org/
Wickham, H., & Grolemund, G. (2017). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data (capítulo 3). O’Reilly Media. https://r4ds.had.co.nz/
Wickham, H., Navarro, D., & Pedersen, T. L. (s.f.). ggplot2: Elegant graphics for data analysis. https://ggplot2-book.org/
9.2 Resumen
R proporciona una gran cantidad de funciones para la elaboración de gráficos estadísticos. En este capítulo, se describen algunos de los paquetes que contienen estas funciones y se ejemplifican varios tipos de gráficos. Específicamente, se estudia el paquete ggplot2, para la creación declarativa de gráficos y el paquete plotly, para graficación interactiva.
Adicionalmente, se introducen el paquete DT, para la creación de tablas interactivas, y el paquete readr, para lectura de datos tabulares. También algunos paquetes con conjuntos de datos de ejemplo y para estilos de ggplot2.
9.3 Instalación y carga
Los paquetes pueden instalarse con la función install.packages().
Una vez instalados, todos los paquetes pueden cargarse con la función library():
# Carga de todos los paquetes de Tidyverse (opcional).
# Si se hace, no es necesario cargar ggplot2 y readr por separado.
library(tidyverse)
# Carga de ggplot2
library(ggplot2)
# Carga de readr
library(readr)
# Carga de plotly
library(plotly)
# Carga de DT
library(DT)
# Carga de dplyr
library(dplyr)9.4 Conjuntos de datos de ejemplo
9.4.1 mpg
mpg es uno de los conjuntos de datos de ejemplo que se incluyen junto con el paquete ggplot2. Contiene observaciones para 38 modelos de automóviles, recopiladas por la Agencia de Protección Ambiental de los Estados Unidos, y un conjunto de variables relacionadas con el consumo de combustible.
En el siguiente bloque de código, se utiliza el paquete DT, para desplegar las observaciones de mpg en una tabla.
# Tabla de datos de mpg
mpg |>
datatable(options = list(
pageLength = 5,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))9.4.2 diamonds
diamonds es otro de los conjuntos de datos de ejemplo de ggplot2. Contiene observaciones de más de 50000 diamantes, incluyendo su precio, color, claridad y otros atributos.
En el siguiente bloque de código, se utiliza el paquete DT, para desplegar las observaciones de diamonds en una tabla.
# Tabla de datos de diamonds
diamonds |>
datatable(options = list(
pageLength = 5,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))9.4.3 gapminder
Es un extracto de los datos disponibles en Gapminder.org, una organización son fines de lucro que promueve el desarrollo global y el cumplimiento de los Objetivos de Desarrollo del Milenio de las Naciones Unidas, a través de la estadística y la información general sobre desarrollo social, económico y ambiental a nivel local, nacional y global.
Se distribuye en el paquete gapminder, el cual contiene el data frame gapminder, que incluye datos de esperanza de vida, producto interno bruto y población de 142 países, para cada cinco años, entre 1952 y 2007.
# Instalación de gapminder
install.packages("gapminder")# Carga de gapminder
library(gapminder)La siguiente tabla muestra los datos de gapminder para el año 2007.
# Tabla de datos de gapminder
gapminder |>
filter(year == 2007) |> # filtro para el año 2007
datatable(options = list(
pageLength = 5,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))9.4.4 Casos de COVID-19 en Costa Rica
Estos datos son publicados por el Ministerio de Salud de Costa Rica en https://geovision.uned.ac.cr/oges/. Se distribuyen en archivos CSV, incluyendo un archivo de datos generales para todo el país y varios archivos con datos por cantón. La fecha de la última actualización es 2022-05-30.
Alternativamente, puede descargar los archivos necesarios de los siguientes enlaces:
El siguiente bloque de código, carga y transforma los datos generales de COVID-19 con funciones de readr y dplyr. La función read_delim() de readr, lee datos de formatos tabulares (ej. CSV, TSV) y, entre otras ventajas, permite cargar solo las columnas especificadas en el argumento col_select.
# Carga del archivo CSV de entrada en un dataframe
# con la función read_delim() de readr
covid_general <-
read_delim(
file = "datos/ministerio-salud/covid/05_30_22_CSV_GENERAL.csv",
col_select = c(
"FECHA",
"positivos",
"activos",
"RECUPERADOS",
"fallecidos",
"nue_posi",
"nue_falleci",
"salon",
"UCI"
) # lista de columnas que se leen del archivo
)
# Cambio de nombre de columnas
covid_general <-
covid_general |>
rename(
fecha = FECHA,
recuperados = RECUPERADOS,
nuevos_positivos = nue_posi,
nuevos_fallecidos = nue_falleci,
uci = UCI
)
# Cambio de tipo de datos de la columna fecha, de str a date
covid_general <-
covid_general |>
mutate(fecha = as.Date(fecha, format = "%d/%m/%Y"))La siguiente tabla muestra los datos generales de COVID-19.
# Tabla de datos de COVID generales
covid_general |>
datatable(options = list(
pageLength = 5,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))Seguidamente, se cargan y transforman los datos cantonales de casos positivos.
# Carga del archivo CSV de entrada en un dataframe
# con la función read_delim() de readr
covid_cantonal_positivos <-
read_delim(
file = "datos/ministerio-salud/covid/05_30_22_CSV_POSITIVOS.csv",
locale = locale(encoding = "WINDOWS-1252"), # para procesar las tildes
col_select = c("provincia", "canton", "30/05/2022")
)
# Cambio de nombre de columnas
covid_cantonal_positivos <-
covid_cantonal_positivos |>
rename(
positivos = '30/05/2022'
)
# Borrado de filas con valor NA u "Otros"
# en la columna canton
covid_cantonal_positivos <-
covid_cantonal_positivos |>
filter(!is.na(canton) & canton != "Otros")La siguiente tabla muestra los datos cantonales de casos positivos de COVID-19.
# Tabla de datos de COVID cantonales positivos
covid_cantonal_positivos |>
datatable(options = list(
pageLength = 5,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))9.5 Características generales
9.5.1 ggplot2
ggplot2 es un sistema para la creación declarativa de gráficos, creado por Hadley Wickham en 2005. Está basado en el libro The Grammar of Graphics, de Leland Wilkinson, un esquema general para visualización de datos que descompone un gráfico en sus principales componentes semáticos, tales como capas y geometrías.
9.5.1.1 Principales componentes de un gráfico
De acuerdo con The Grammar of Graphics, los tres principales componentes de un gráfico son:
- Datos (observaciones y variables).
- Conjunto de mapeos de las variables del conjunto de datos a propiedades visuales (aesthetics) del gráfico, tales como posición en el eje x, posición en el eje y, color, tamaño y forma, entre otras.
- Al menos una capa, la cual describe como graficar cada observación. Por lo general, las capas se crean con funciones de geometrías (ej. puntos, líneas, barras).
9.5.1.2 Opciones básicas
ggplot2 implementa un gráfico estadístico por medio de la función ggplot(), cuya sintaxis básica puede resumirse de la siguiente forma:
ggplot(data = <DATOS>) +
<FUNCION_GEOMETRIA>(mapping = aes(<MAPEOS>))El llamado a ggplot() crea un sistema de coordenadas (i.e. un “canvas”), al cual se le agregan capas. Su primer argumento es <DATOS>, el cual es usualmente un dataframe o un tibble.
La función aes() realiza los mapeos (<MAPEOS>) de las variables del conjunto de datos a las propiedades visuales del gráfico. Las capas se crean con funciones de geometrías (<FUNCION_GEOMETRIA>) como geom_point(), geom_bar() o geom_histogram(), entre muchas otras. Note el uso del operador + para agregar las capas al gráfico.
Como ejemplo, se crea un gráfico de dispersión que muestra la variable engine displacement o cilindrada (displ) en el eje X, y la variable highway miles per gallon o millas por galón en autopista (hwy) en el eje Y.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))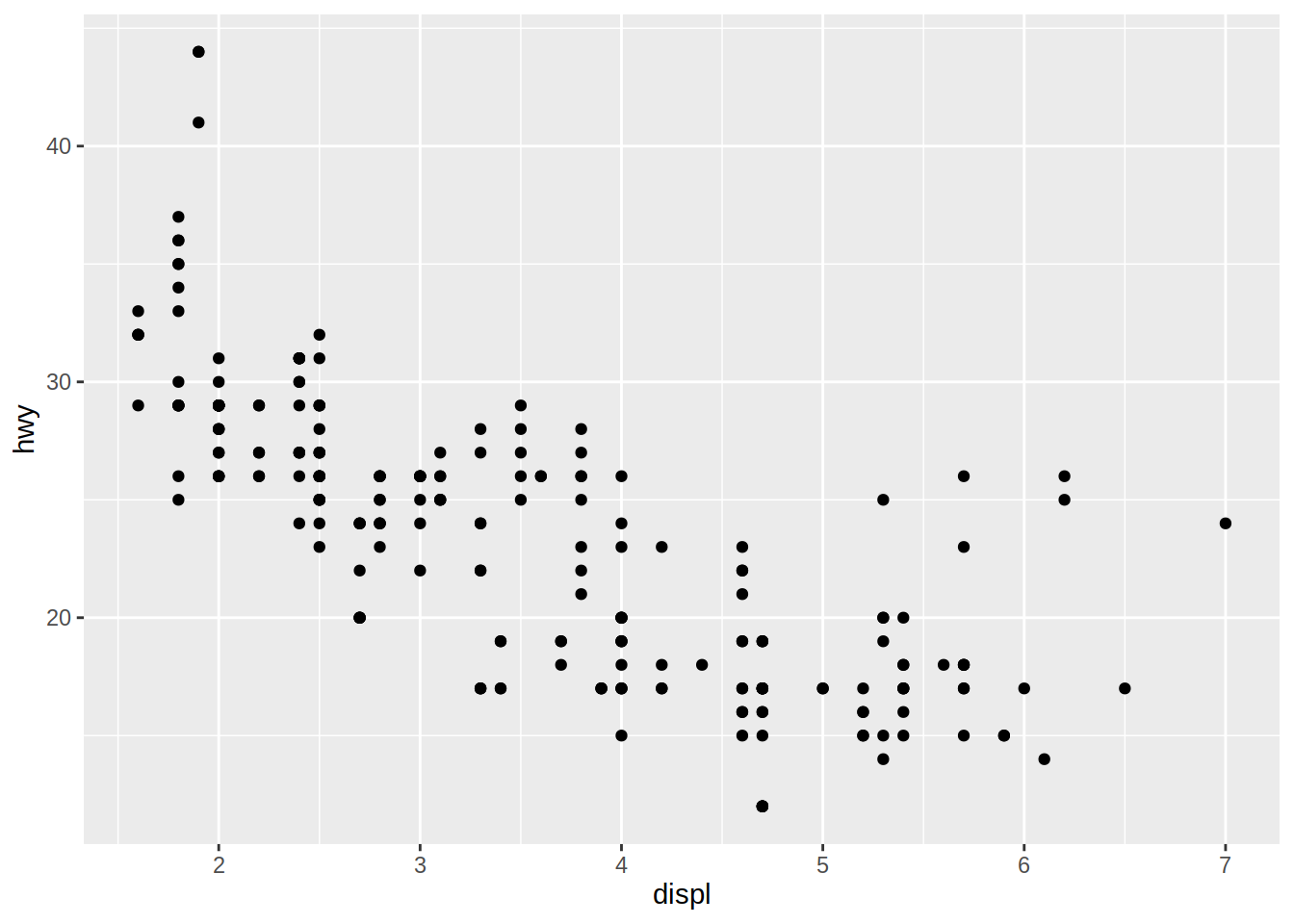
El bloque de código anterior puede reescribirse mediante un pipe, para pasar el conjunto de datos a ggplot(). También puede llamarse a aes() como un argumento de ggplot() y no de la función de geometría. Esto último acostumbra hacerse cuando los mapeos de las variables a las propiedades estéticas son los mismos en todas las capas del gráfico.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
mpg |>
ggplot(aes(x = displ, y = hwy)) +
geom_point()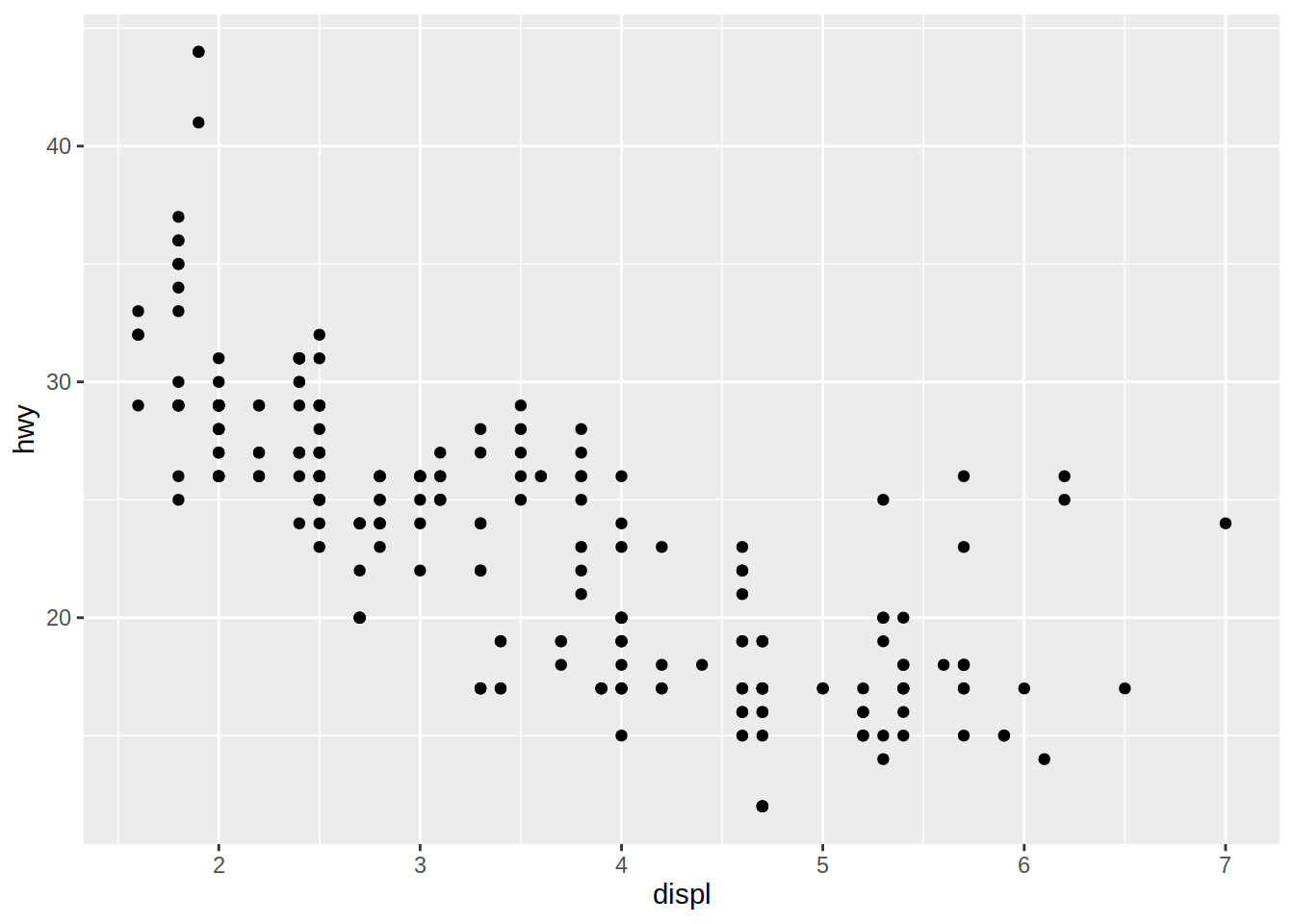
El gráfico muestra una relación negativa entre el tamaño del motor (displ) y la eficiencia en el uso del combustible (hwy). En otras palabras, los vehículos con motores grandes usan más combustible.
9.5.1.3 Variables adicionales
Se pueden incluir variables adicionales en el gráfico mediante su mapeo a otras propiedades visuales. En el siguiente bloque de código, la variable tipo de automóvil (class), se mapea a la propiedad color.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de automóvil
mpg |>
ggplot(aes(x = displ, y = hwy, color = class)) +
geom_point()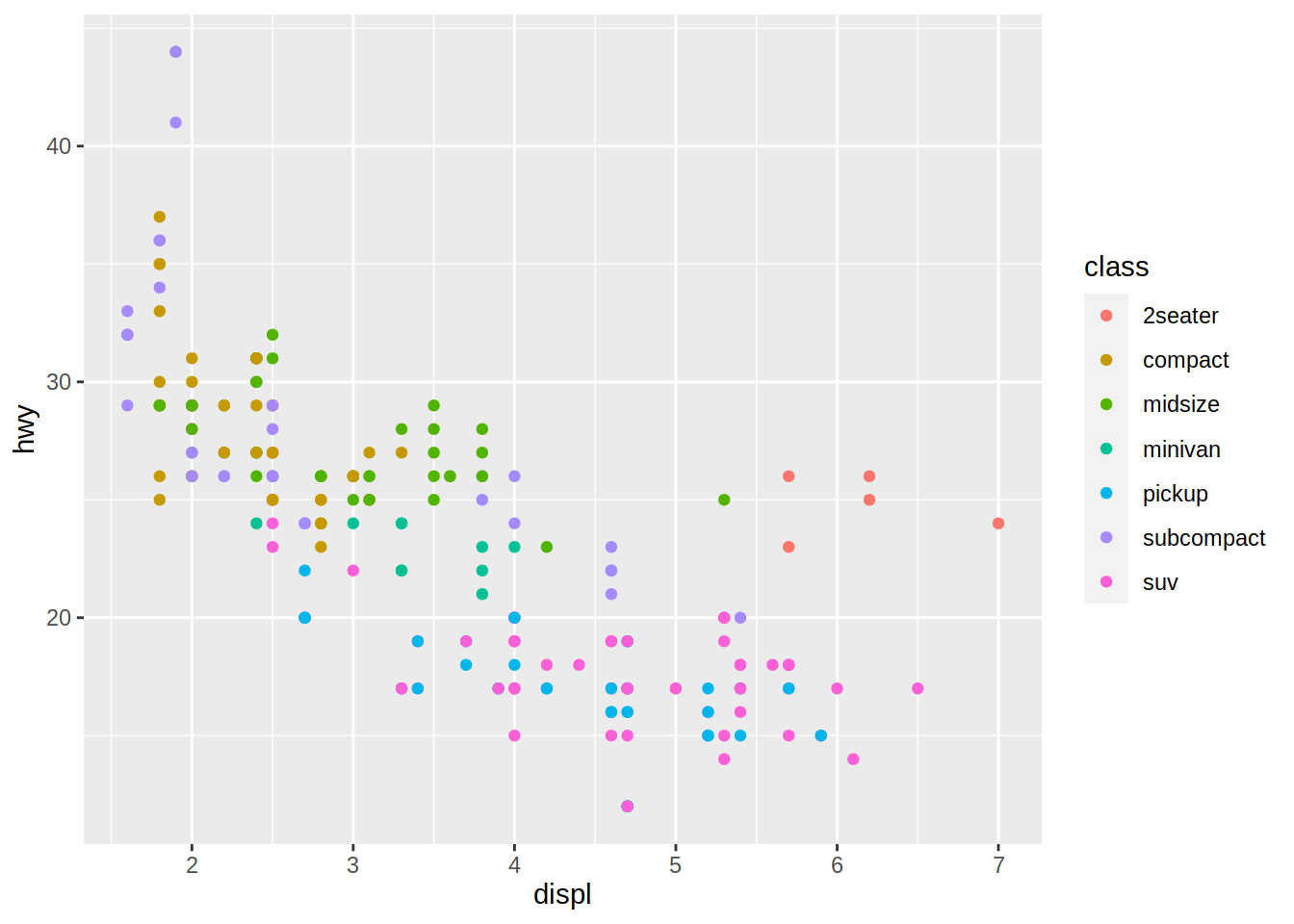
La misma variable puede mapearse a la propiedad visual shape (forma). La categoría de los SUV no se incluye en el gráfico debido a que ggplot solo muestra, por defecto, seis formas diferentes cuando se asignan de manera automática (el problema puede solucionarse si se asignan explicitamente).
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# con formas de puntos correspondientes al tipo de automóvil
mpg |>
ggplot(aes(x = displ, y = hwy, shape = class)) +
geom_point()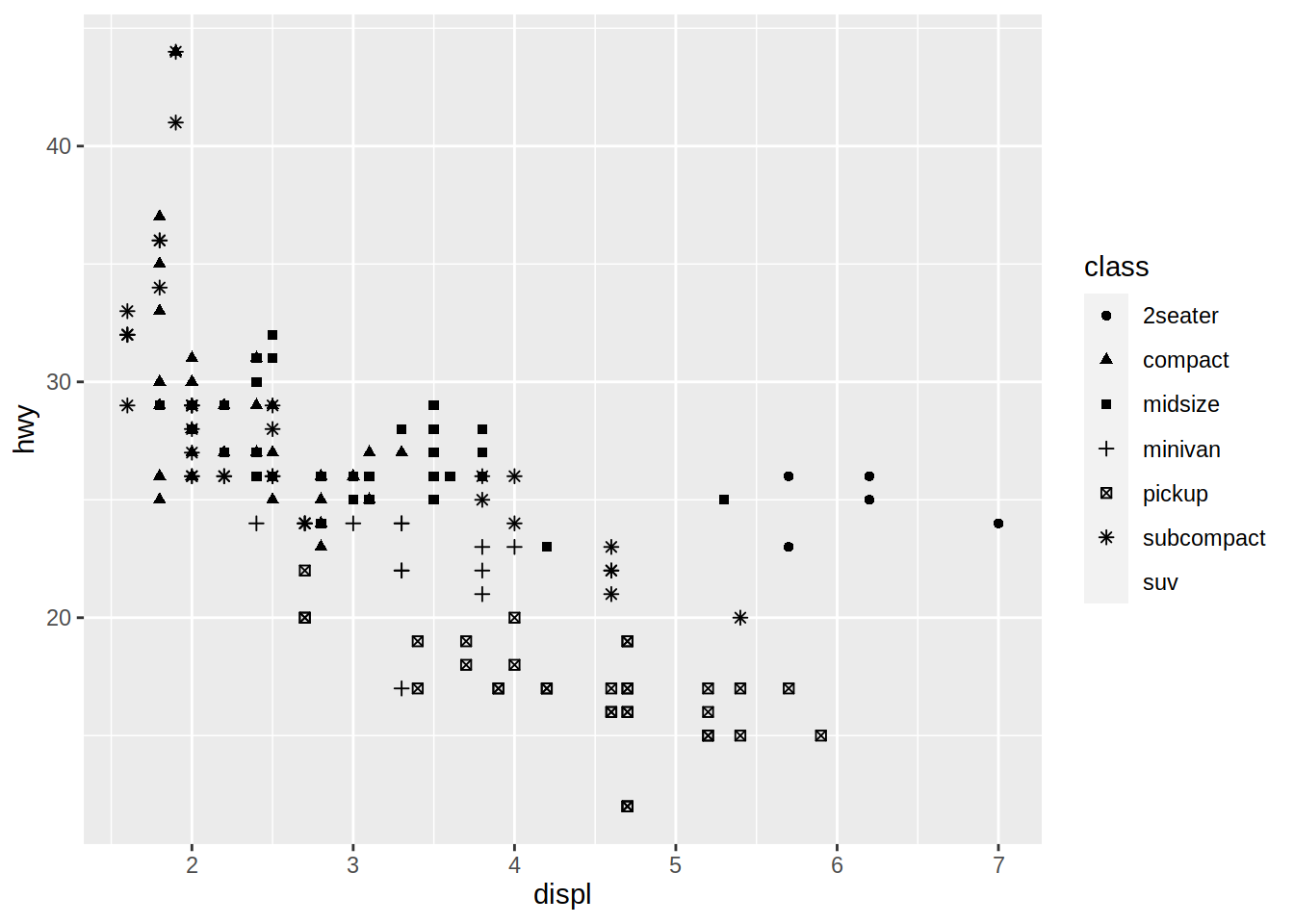
9.5.1.4 Capas adicionales
Un mismo gráfico puede contener múltiples capas, cada una con su propia función de geometría. El siguiente bloque de código agrega una capa con la función geom_smooth(), la cual muestra una curva de tendencia.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# + curva de tendencia
mpg |>
ggplot(aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth()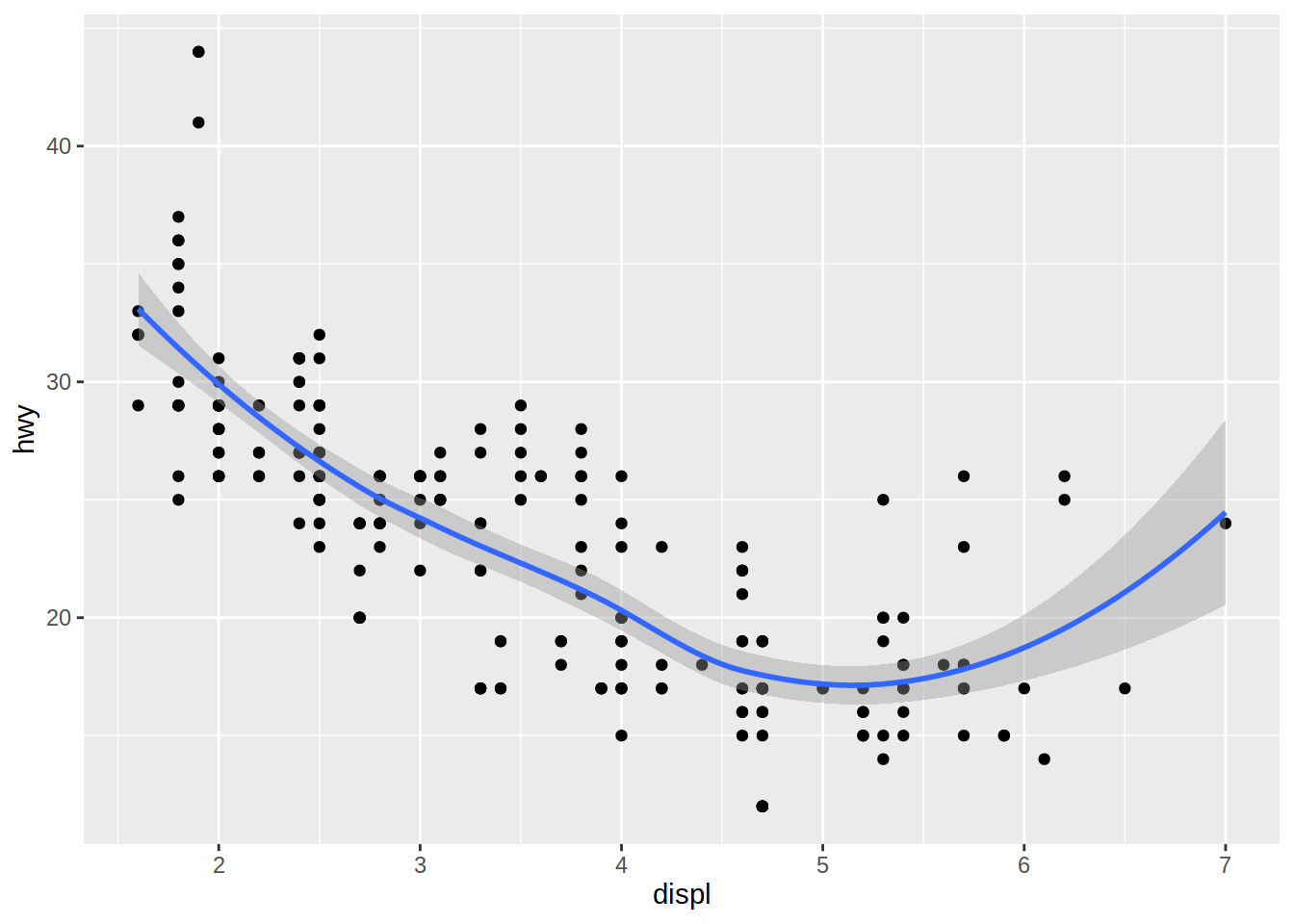
En el siguiente ejemplo, se mapea la variable tipo de tracción (drv) a la propiedad visual del color, tanto para la capa de puntos como para la de la curva de tendencia.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de tracción
# + curva de tendencia
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth()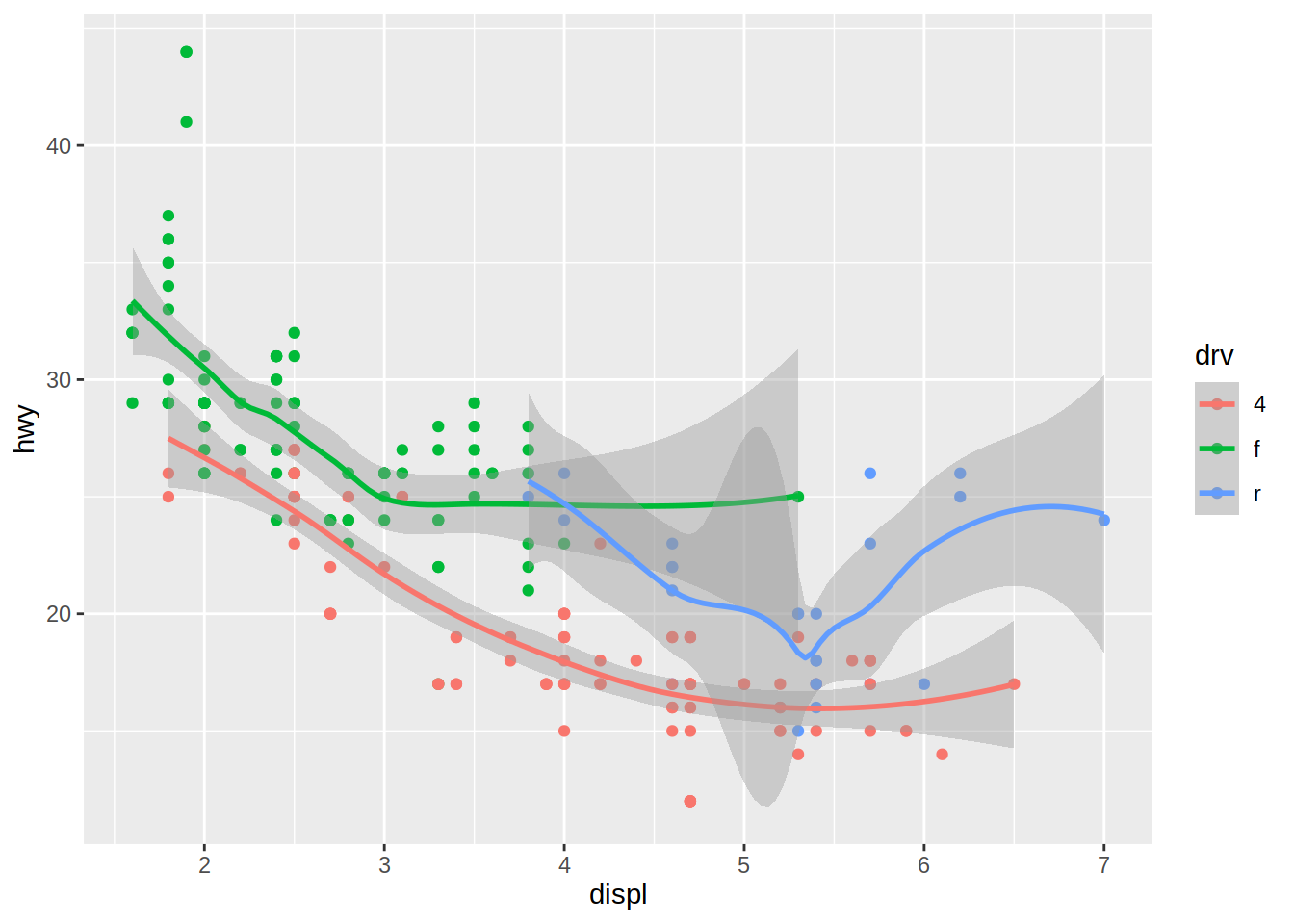
El siguiente gráfico muestra varias capas, correspondientes a geometrías de puntos y curvas de tendencia. aes() se llama en las funciones de geometrías debido a que cada una realiza mapeos diferentes.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# + gráfico de dispersión de cilindrada vs millas por galón en ciudad
# + curvas de tendencias
mpg |>
ggplot(aes(x = displ)) +
geom_point(aes(y = hwy), color = "green") +
geom_smooth(aes(y = hwy), color = "green") +
geom_point(aes(y = cty), color = "red") +
geom_smooth(aes(y = cty), color = "red") `geom_smooth()` using method = 'loess' and formula = 'y ~ x'
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'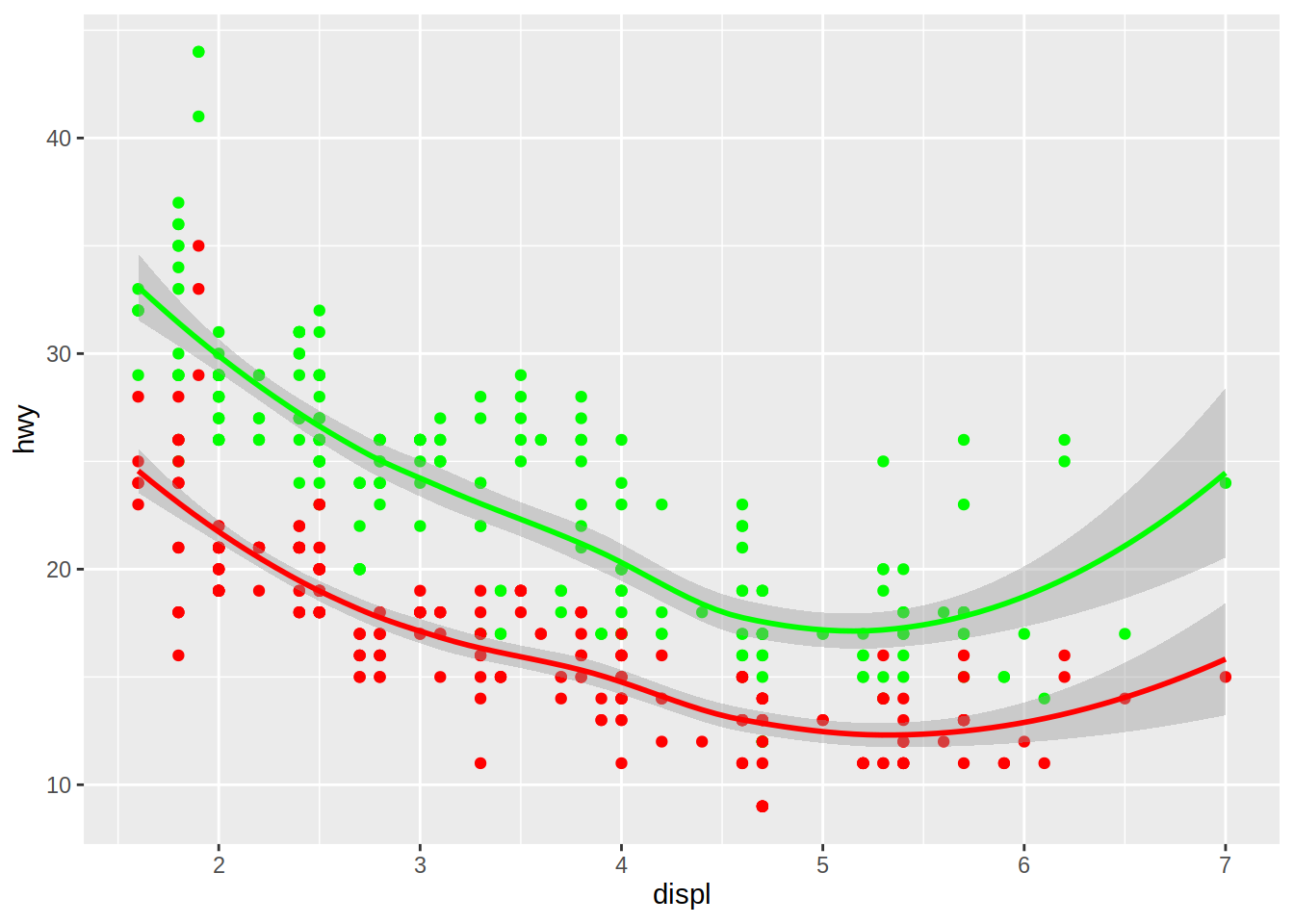
9.5.1.5 Facets
Como se mostró anteriormente, una forma de mostrar variables adicionales en un gráfico es mediante propiedades visuales (color, forma, tamaño, etc.). Otra forma es mediante el uso de facets, los cuales dividen un gráfico en subgráficos, de acuerdo con los valores de una variable. Este método es particularmente apropiado cuando la variable adicional es categórica o discreta.
La función facet_wrap() divide un gráfico de acuerdo con una sola variable. El primer argumento es una fórmula, la cual se crea con el caracter ~ seguido por el nombre de una variable.
En el siguiente bloque de código, se generan facets para el gráfico de dispersión de cilindrada vs millas por galón en autopista, de acuerdo con el tipo de automóvil. Es decir, un facet (subgráfico) por cada tipo de automóvil.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# + facets por tipo de automóvil
mpg |>
ggplot(aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~ class, nrow = 2)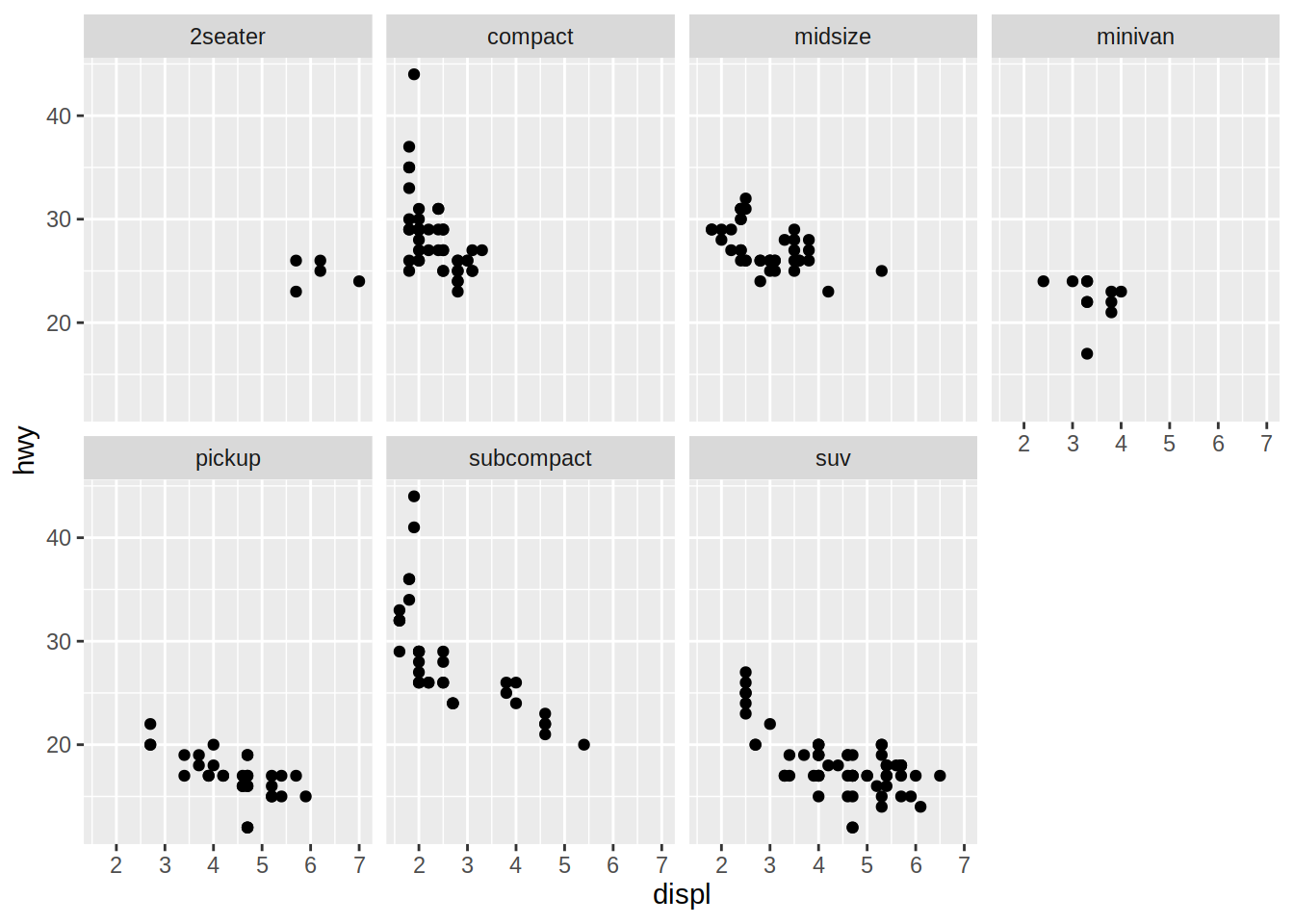
La función facet_grid() genera los subgráficos con la combinación de dos variables. El primer argumento es también una fórmula, la cual contiene dos variables separadas por ~.
En el siguiente bloque de código, se generan facets para el gráfico de dispersión de cilindrada vs millas por galón en autopista, de acuerdo con el tipo de automóvil y el tipo de tracción.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# + facets por tipo de automóvil y tipo de tracción
mpg |>
ggplot(aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(class ~ drv)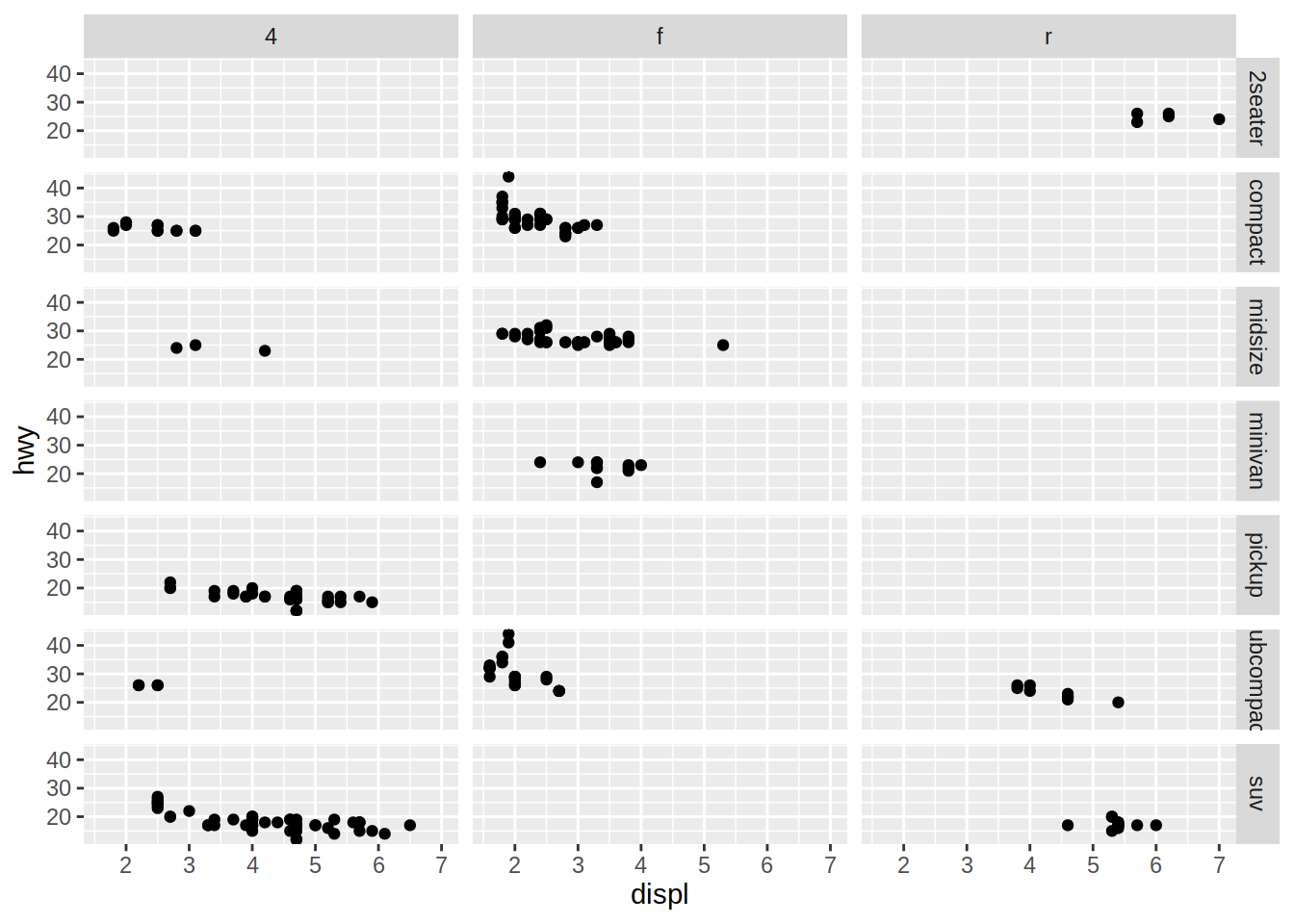
9.5.1.6 Títulos, etiquetas y estilos
ggplot2 incluye las funciones ggtitle(), xlab(), ylab() y labs(), las cuales permiten agregar títulos, subtítulos, etiquetas en los ejes y de otros tipos a un gráfico.
Algunas de las opciones que ofrecen estas funciones se ilustran en el siguiente gráfico.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de tracción con título, subtítulo y etiquetas
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth() +
ggtitle("Cilindrada vs rendimiento en autopista") +
xlab("Cilindrada (l)") +
ylab("Rendimiento en autopista (mpg)") +
labs(subtitle = "Datos de 38 modelos de automóviles de años entre 1999 y 2008",
caption = "Fuente: United States Environmental Protection Agency (EPA)",
color = "Tipo de tracción")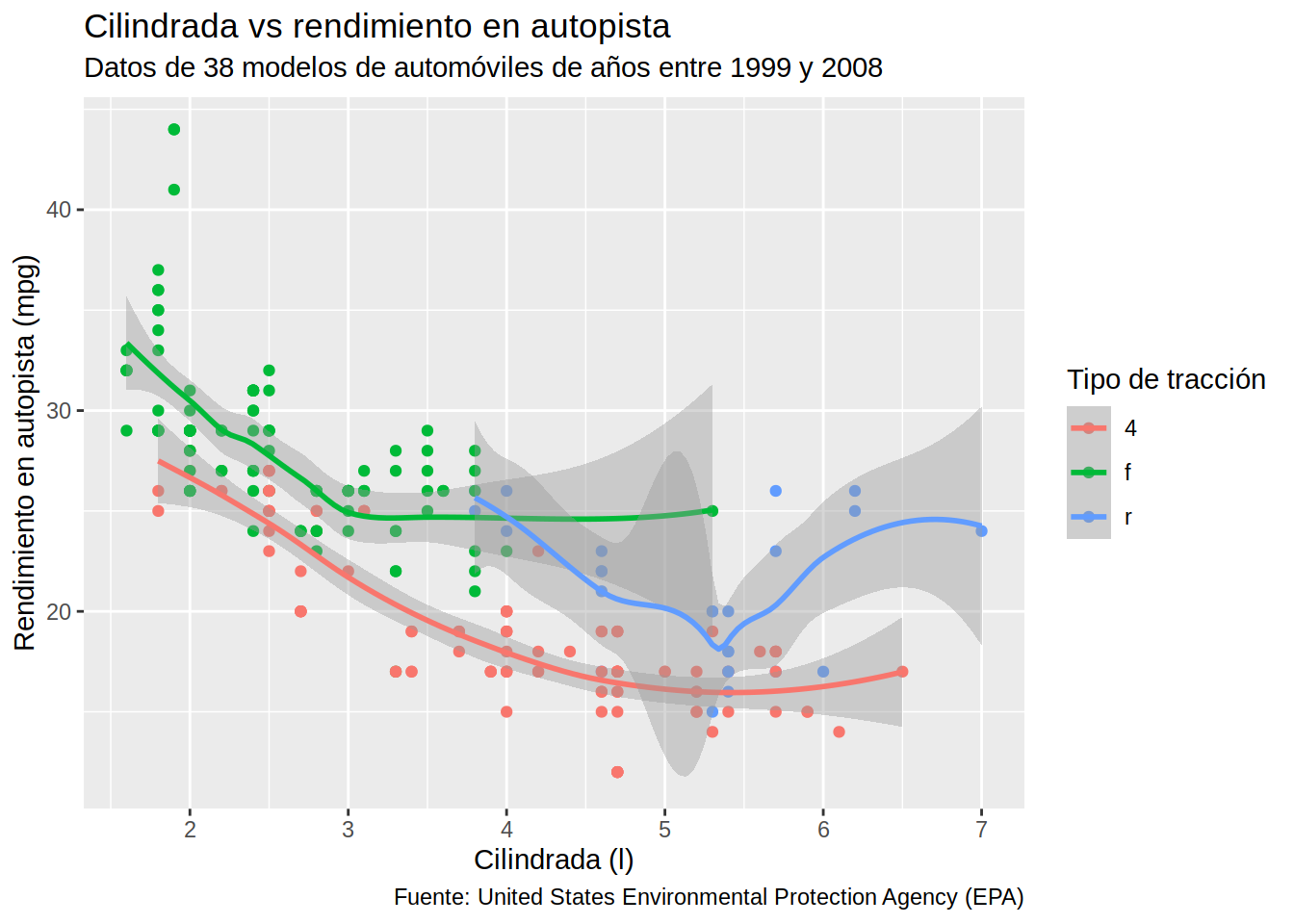
El títulos y las etiquetas de los ejes se pueden agregar también mediante argumentos de labs().
9.5.1.6.1 Temas
ggplot2 incluye un conjunto de temas (estilos) que pueden mejorar el aspecto visual de los gráficos.
# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de tracción con título, subtítulo, etiquetas y tema
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth() +
ggtitle("Cilindrada vs rendimiento en autopista") +
xlab("Cilindrada (l)") +
ylab("Rendimiento en autopista (mpg)") +
labs(subtitle = "Datos de 38 modelos de automóviles de años entre 1999 y 2008",
caption = "Fuente: United States Environmental Protection Agency (EPA)",
color = "Tipo de tracción") +
theme_bw() # tema de ggplot2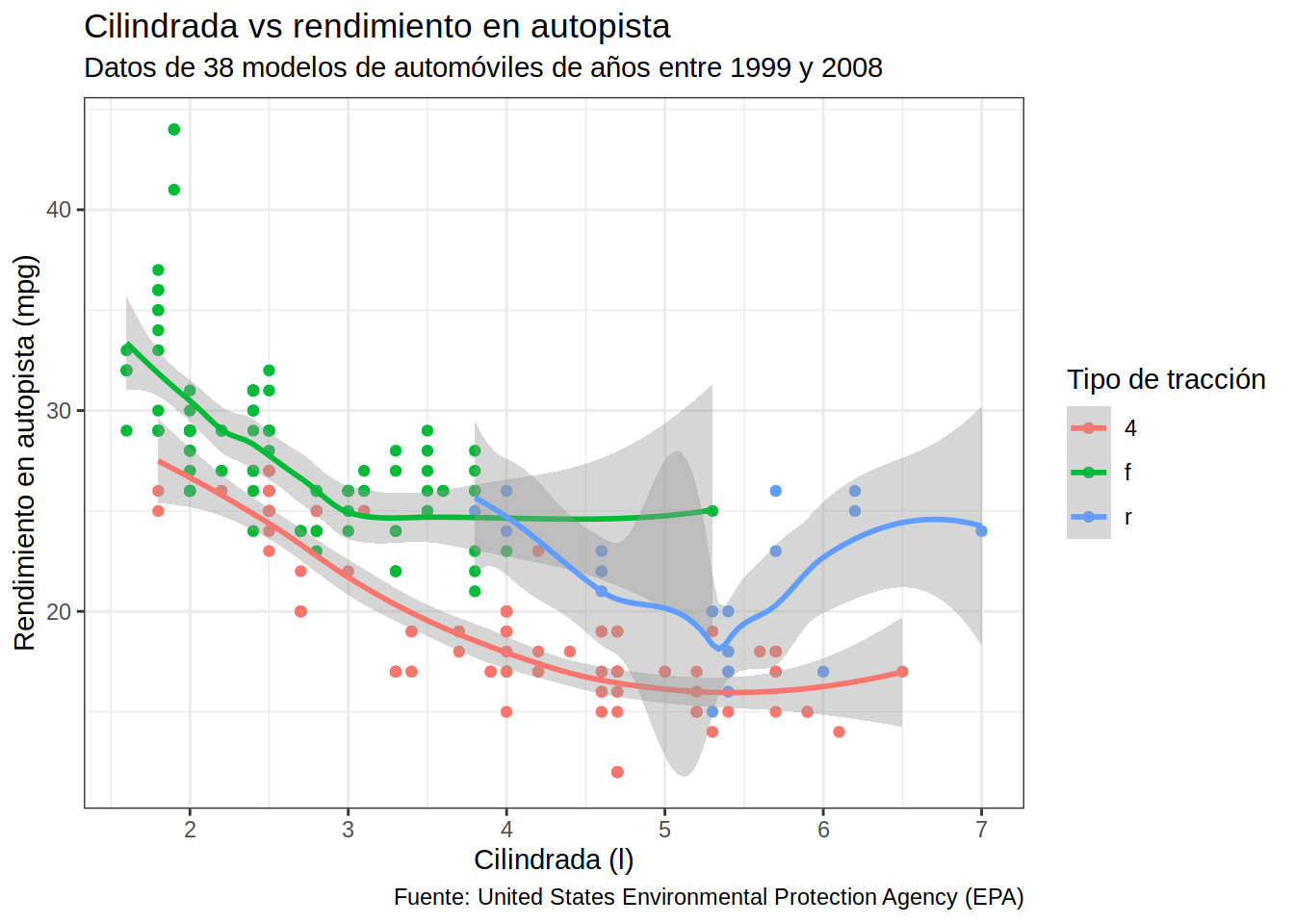
Existen paquetes que ofrecen temas adicionales como, por ejemplo, ggthemes.
# Instalación de ggthemes
install.packages("ggthemes")# Carga de ggthemes
library(ggthemes)# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de tracción con título, subtítulo, etiquetas y tema de ggthemes
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth() +
ggtitle("Cilindrada vs rendimiento en autopista") +
xlab("Cilindrada (l)") +
ylab("Rendimiento en autopista (mpg)") +
labs(subtitle = "Datos de 38 modelos de automóviles de años entre 1999 y 2008",
caption = "Fuente: United States Environmental Protection Agency (EPA)",
color = "Tipo de tracción") +
theme_economist() # tema de ggthemes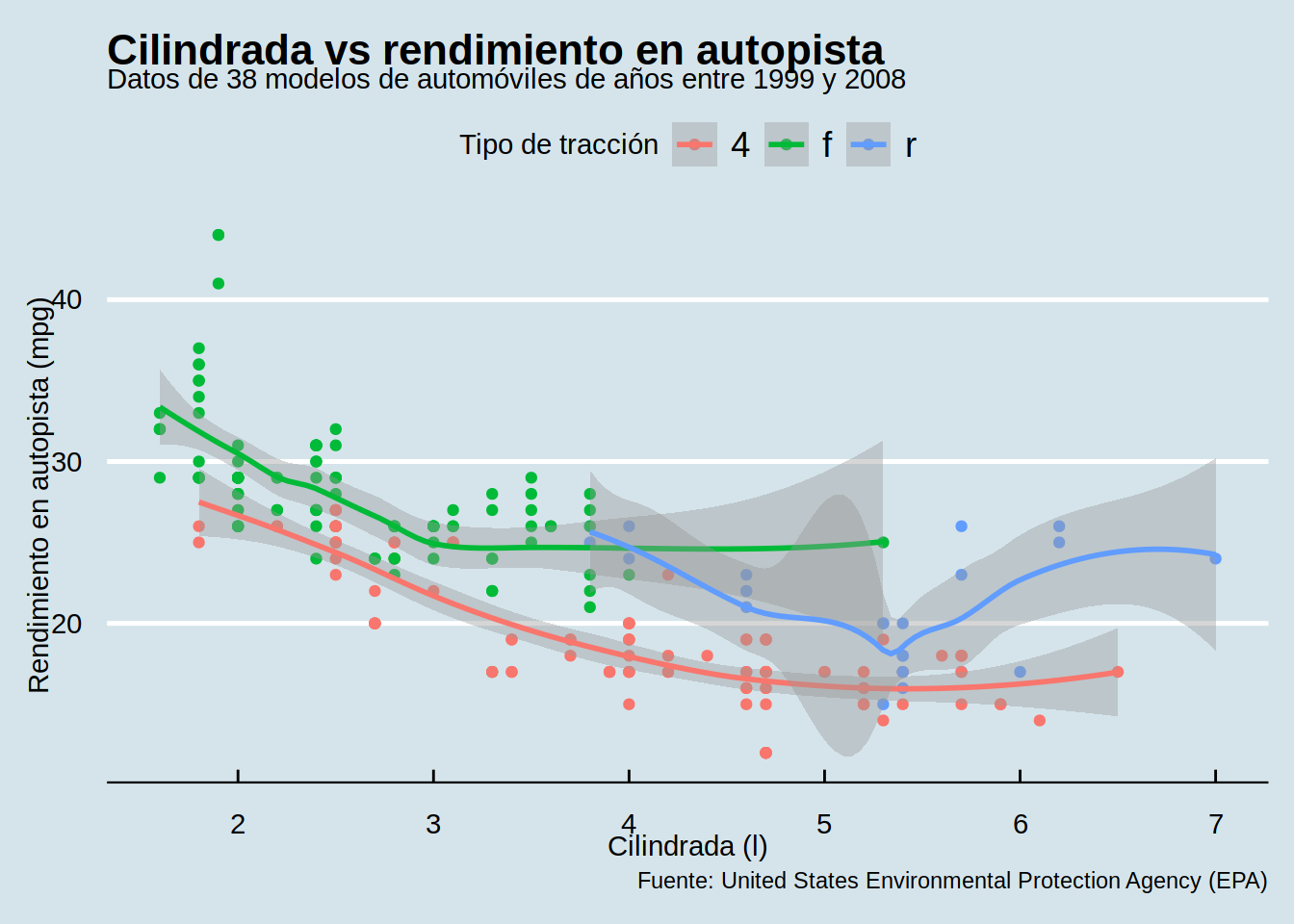
Otro paquete de temas y recursos relacionados (escalas de colores, fuentes, etc.) es hrbrthemes.
# Instalación de hbrthemes
install.packages("hrbrthemes")# Carga de hbrthemes
library(hrbrthemes)# Gráfico de dispersión de cilindrada vs millas por galón en autopista
# coloreado por tipo de tracción con título, subtítulo, etiquetas y tema de hbrthemes
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth() +
ggtitle("Cilindrada vs rendimiento en autopista") +
xlab("Cilindrada (l)") +
ylab("Rendimiento en autopista (mpg)") +
labs(subtitle = "Datos de 38 modelos de automóviles de años entre 1999 y 2008",
caption = "Fuente: United States Environmental Protection Agency (EPA)",
color = "Tipo de tracción") +
theme_ipsum() # tema de hrbrthemes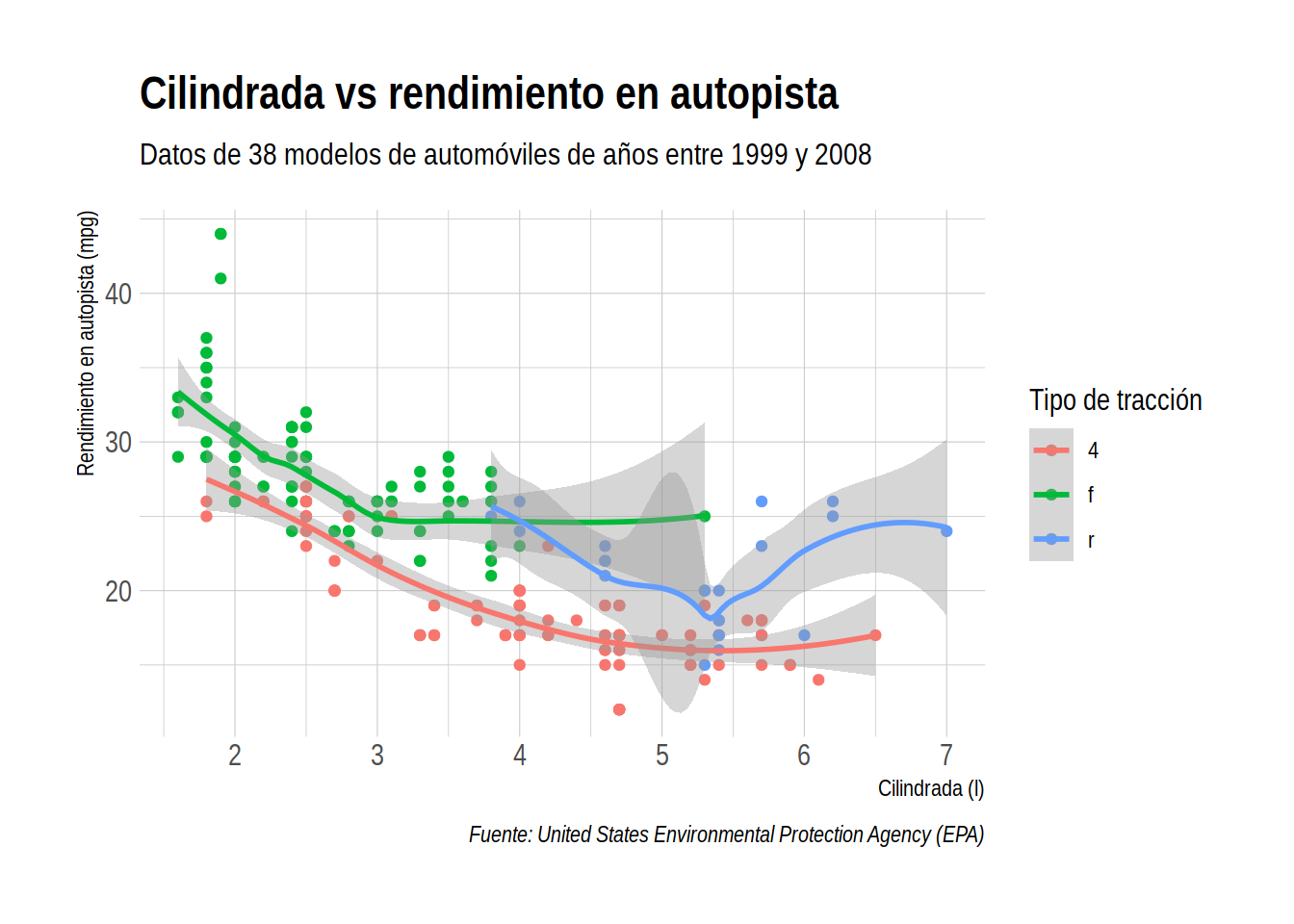
9.5.1.6.2 Colores
ggplot2 incluye múltiples funciones para escalas de colores, entre las que pueden mencionarse:
- scale_color_brewer(): para escalas de colores secuenciales, divergentes y cualitativas de ColorBrewer.
- scale_color_viridis_d(): para escalas viridis, diseñadas para mejorar la legibilidad de gráficos para lectores con formas comunes de daltonismo y discapacidades relacionadas con la percepción de colores.
- scale_color_manual(): para especificar directamente los colores a utilizar.
El siguiente bloque de código genera un gráfico de dispersión para los datos de diamonds. Muestra el peso en quilates (carat) de los diamantes en el eje X y su precio (price) en el eje Y. La variable correspondiente a su claridad (clarity) se muestra mediante el color de los puntos, de acuerdo con una escala de ColorBrewer.
# Gráfico de dispersión de peso vs precio de diamantes
# coloreado por claridad
diamonds |>
ggplot(aes(x = carat, y = price, color = clarity)) +
geom_point() +
ggtitle("Peso vs precio de diamantes") +
xlab("Peso (quilates)") +
ylab("Precio ($ EE.UU.)") +
labs(color = "Claridad\n(I1=peor IF=mejor)") +
scale_colour_brewer(palette = "YlOrBr", direction = -1) +
theme_ipsum() # tema de hrbrthemes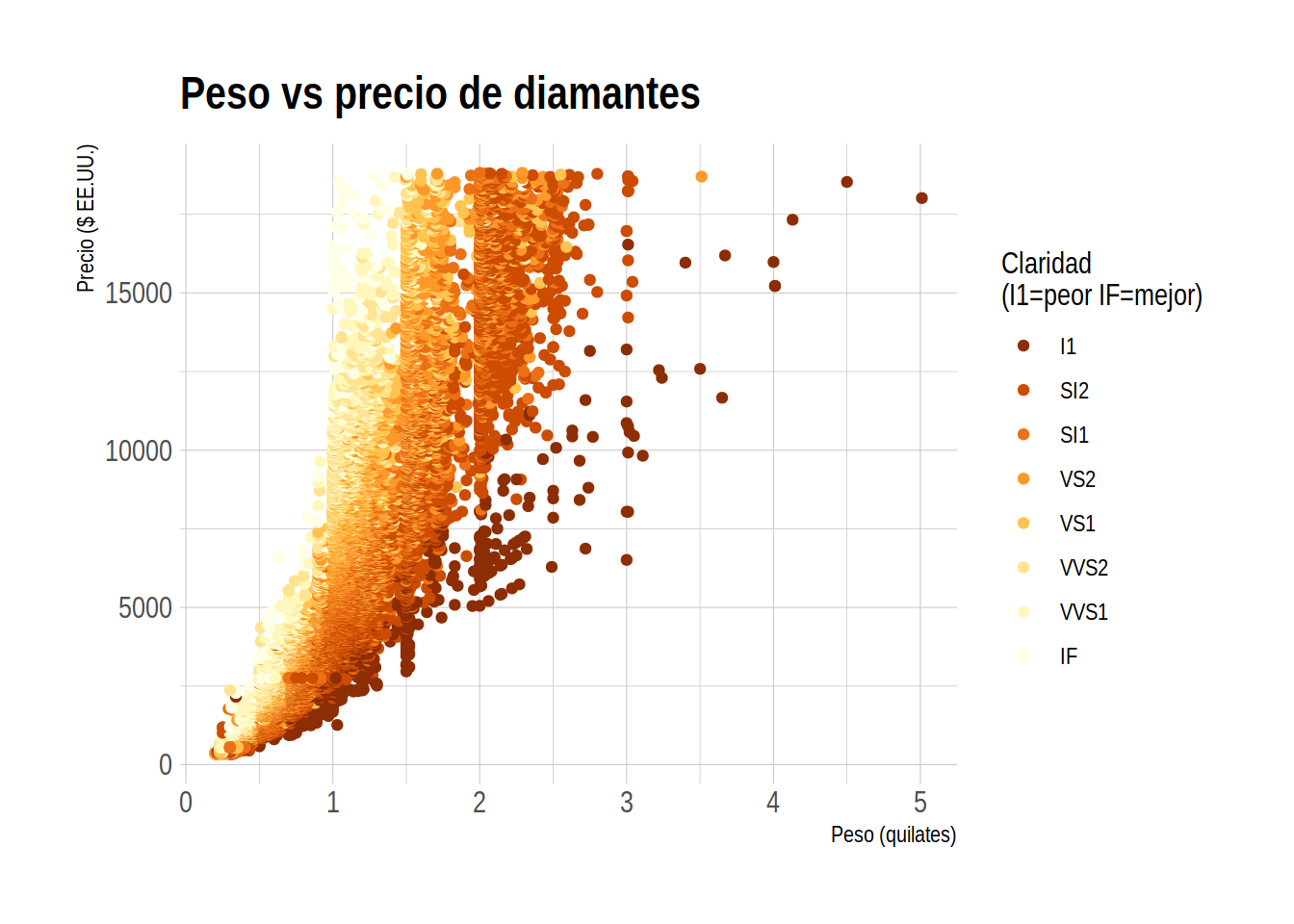
Para más información sobre etiquetas, estilos, colores y otros temas relacionados en ggplot2, se recomienda leer ggplot2: Elegant Graphics for Data Analysis - Themes.
9.5.1.7 Opciones avanzadas
En las secciones y ejemplos anteriores, se han estudiado las opciones básicas para crear un gráfico en ggplot2: datos, mapeos de variables a propiedades visuales y capas. También se mostró la forma de implementar facets, como un mecanismo para visualizar variables adicionales y algunos recursos para mejorar la apariencia de los gráficos.
ggplot2 incluye otras opciones para la creación de gráficos, como transformaciones estadísticas, transformaciones de sistemas de coordenadas y posicionamiento de las geometrías, las cuales pueden esquematizarse de la siguiente forma:
ggplot(data = <DATOS>) +
<FUNCION_GEOMETRIA>(
mapping = aes(<MAPEOS>),
stat = <ESTADISTICA>,
position = <POSICION>
) +
<FUNCION_COORDENADAS> +
<FUNCION_FACET>En las secciones siguientes, se explicarán y ejemplificarán alguna de estas opciones.
9.5.2 plotly
plotly R es una biblioteca para gráficos interactivos que forma parte del grupo de bibliotecas de graficación de Plotly, el cual también incluye bibliotecas para otros lenguajes como Python, Julia, F# y MATLAB. Plotly fue originalmente escrita en JavaScript, por lo que es particularmente adecuada para gráficos interactivos en la Web.
plotly implementa la función ggplotly(), la cual convierte graficos de ggplot2 a plotly, haciéndolos interactivos.
El siguiente bloque de código muestra un gráfico generado con ggplot2 y convertido a plotly con la función ggplotly().
# Gráfico ggplot2
grafico_ggplot2 <-
mpg |>
ggplot(aes(x = displ, y = hwy, color = drv)) +
geom_point(aes(
text = paste0( # se especifican los datos que se muestran al pasar el ratón
"Cilindrada: ",
displ,
"\n",
"Rendimiento en autopista: ",
hwy,
"\n",
"Tipo de tracción: ",
drv
)
)) +
geom_smooth() +
ggtitle("Cilindrada vs rendimiento en autopista") +
xlab("Cilindrada (l)") +
ylab("Rendimiento en autopista (mpg)") +
labs(subtitle = "Datos de 38 modelos de automóviles de años entre 1999 y 2008",
caption = "Fuente: United States Environmental Protection Agency (EPA)",
color = "Tipo de tracción") +
theme_ipsum()
# Gráfico plotly
ggplotly(grafico_ggplot2, tooltip = "text") |>
config(locale = 'es') # para mostrar los controles en español9.6 Tipos de gráficos
En esta sección, se ejemplifican varios tipos de gráficos, los cuales se construyen con ggplot2 y luego se convierten a plotly.
9.6.1 Histogramas
Un histograma es una representación gráfica de la distribución de una variable numérica en forma de barras (llamadas en inglés bins). La longitud de cada barra representa la frecuencia de un rango de valores de la variable. La graficación de la distribución de las variables es, frecuentemente, una de las primeras tareas que se realiza cuando se explora un conjunto de datos.
En ggplot2, los histogramas se implementan con la función geom_histogram().
El siguiente bloque de código muestra, mediante un histograma, la distribución del producto interno bruto (PIB) per cápita para el año 2007, entre los países incluídos en gapminder.
# Histograma ggplot2 de distribución del PIB per cápita en 2007
histograma_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap)) +
geom_histogram(bins = 10) + # cantidad de bins
ggtitle("Distribución del PIB per cápita en 2007") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Frecuencia") +
labs(subtitle = "Datos de 14o países", caption = "Fuente: Gapminder.org") +
theme_economist()
# Histograma plotly
ggplotly(histograma_ggplot2) |>
config(locale = 'es')Warning: The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?La función geom_density() permite crear una estimación de densidad del kernel (Kernel Density Estimation o KDE), una curva que muestra la densidad de los datos.
# Histograma ggplot2 de distribución del PIB per cápita en 2007
histograma_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap)) +
geom_histogram(aes(y = ..density..), # argumento necesario para crear la curva KDE
bins = 10) + # cantidad de bins
geom_density() +
ggtitle("Distribución del PIB per cápita en 2007") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Frecuencia") +
labs(subtitle = "Datos de 140 países", caption = "Fuente: Gapminder.org") +
theme_economist()
# Histograma plotly
ggplotly(histograma_ggplot2) |>
config(locale = 'es')Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.
ℹ The deprecated feature was likely used in the ggplot2 package.
Please report the issue at <]8;;https://github.com/tidyverse/ggplot2/issueshttps://github.com/tidyverse/ggplot2/issues]8;;>.Warning: The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?En el siguiente bloque, se incluye en el gráfico anterior la variable continent a través de la propiedad visual relleno (fill).
# Histograma ggplot2 de distribución del PIB per cápita en 2007 por continente
histograma_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap, fill = continent)) +
geom_histogram(bins = 10) + # cantidad de bins
ggtitle("Distribución del PIB per cápita en 2007 por continente") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Frecuencia") +
labs(subtitle = "Datos de 140 países",
caption = "Fuente: Gapminder.org",
fill = "Continente") +
theme_economist()
# Histograma plotly
ggplotly(histograma_ggplot2) |>
config(locale = 'es')Warning: The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?El gráfico anterior muestra como el PIB per cápita varía considerablemente entre continentes. La misma información puede mostrarse mediante facets.
# Histogramas ggplot2 de distribución del PIB per cápita en 2007 por continente
histograma_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap)) +
geom_histogram(bins = 10) + # cantidad de bins
ggtitle("Distribución del PIB per cápita en 2007 por continente") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Frecuencia") +
labs(subtitle = "Datos de 140 países",
caption = "Fuente: Gapminder.org",
fill = "Continente") +
facet_wrap(~ continent, nrow = 2) +
theme_economist()
# Histograma plotly
ggplotly(histograma_ggplot2) |>
config(locale = 'es')Warning: The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
The following aesthetics were dropped during statistical transformation:
x_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?9.6.2 Gráficos de caja
Un gráfico de caja (boxplot) muestra información de una variable numérica a través de su mediana, sus cuartiles (Q1, Q2 y Q3) y sus valores atípicos.
La figura Figure 9.1 muestra los componentes de un gráfico de caja.
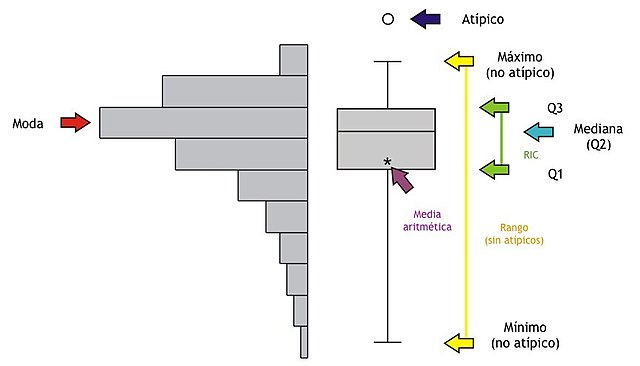
{kind=link}
En ggplot2, los gráficos de caja se implementan con la función geom_boxplot().
El siguiente bloque de código muestra, mediante un gráfico de caja, la distribución del PIB per cápita para el año 2007, entre los países incluídos en gapminder.
# Gráfico de caja ggplot2 de distribución del PIB per cápita en 2007
grafico_caja_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(y = gdpPercap)) +
geom_boxplot() +
ggtitle("Distribución del PIB per cápita en 2007") +
ylab("PIB per cápita ($ EE.UU.)") +
labs(subtitle = "Datos de 140 países", caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de caja plotly
ggplotly(grafico_caja_ggplot2) |>
config(locale = 'es')Warning: The following aesthetics were dropped during statistical transformation:
y_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?En el siguiente bloque, se utiliza la posición en el eje X para mostrar la variable continent y apreciar la distribución del PIB per cápita en cada continente.
# Gráfico de caja ggplot2 de distribución del PIB per cápita en 2007 por continente
grafico_caja_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = continent, y = gdpPercap)) +
geom_boxplot() +
ggtitle("Distribución del PIB per cápita en 2007 por continente") +
ylab("PIB per cápita ($ EE.UU.)") +
labs(subtitle = "Datos de 140 países", caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de caja plotly
ggplotly(grafico_caja_ggplot2) |>
config(locale = 'es')Warning: The following aesthetics were dropped during statistical transformation:
y_plotlyDomain
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?9.6.3 Gráficos de barras
Un gráfico de barras se compone de barras rectangulares con longitud proporcional a estadísticas (ej. frecuencias, promedios, mínimos, máximos) asociadas a una variable categórica o discreta. Las barras pueden ser horizontales o verticales y se recomienda que estén ordenadas según su longitud, a menos que exista un orden inherente a la variable (ej. el orden de los días de la semana). Es uno de los tipos de gráficos estadísticos más antiguos y comunes y tiene la ventaja de ser muy fácil de comprender.
En ggplot2, los histogramas se implementan con las funciones geom_bar(), que se utiliza en gráficos que requieren transformaciones estadísticas, y geom_col(), para gráficos que no requieren estas transformaciones.
9.6.3.1 Barras con transformaciones estadísticas
Los gráficos de barras y otros tipos de gráficos (ej. histogramas, gráficos de caja, líneas de ajuste) pueden requerir de alguna transformación estadística antes de presentar la información. Esta transformación estadística puede ser un conteo, el cálculo de un promedio, un mínimo o un máximo, entre otras opciones.
Por ejemplo, el siguiente gráfico muestra la cantidad de países por continente presentes en el conjunto de datos gapminder para el año 2007. Nótese que este conteo no está presente en ninguna de las variables del conjunto de datos.
# Gráfico de barras con conteo de países por continente para el año 2007
grafico_barras_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = continent)) +
geom_bar() +
ggtitle("Cantidad de países por continente") +
xlab("Continente") +
ylab("Cantidad") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')Para ordenar las barras de acuerdo con el conteo, puede utilizarse la función fct_infreq() del paquete forcats de Tidyerse, para manejo de factores. Tenga en cuenta que la columna continent está definida como un factor.
# Gráfico de barras con conteo de países por continente para el año 2007
grafico_barras_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = fct_infreq(continent))) +
geom_bar() +
ggtitle("Cantidad de países por continente") +
xlab("Continente") +
ylab("Cantidad") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')Si se prefiere el orden inverso, puede utilizarse la función fct_rev() (ej. fct_rev(fct_infreq(continent))).
En un ejemplo similar, se cuenta la cantidad de diamantes por tipo de corte (cut), para el conjunto de datos diamonds.
# Gráfico de barras con conteo de diamantes por corte
grafico_barras_ggplot2 <-
diamonds |>
ggplot(aes(x = fct_rev(cut))) +
geom_bar() +
ggtitle("Cantidad de diamantes por corte") +
xlab("Corte") +
ylab("Cantidad") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')El cálculo de la cantidad de países por continente o el de la cantidad de diamantes por corte, son ejemplos de transformaciones estadísticas. La Figure 9.2 muestra como se realiza este proceso para el gráfico anterior.
![]()
Las barras pueden mostrar otras transformaciones estadísticas a través del uso de los argumentos stat y fun.y de geom_bar(). Por ejemplo, stat = "summary" y fun.y = "mean"generan un gráfico que muestra el promedio de esperanza de vida (lifeExp) para cada continente para el año 2007.
# Gráfico de barras con promedio de esperanza de vida
# para cada continente para el año 2007
grafico_barras_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = fct_infreq(continent), y = lifeExp)) +
geom_bar(stat = "summary", fun.y = "mean") +
ggtitle("Promedio de esperanza de vida por continente en 2007") +
xlab("Continente") +
ylab("Promedio") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')Nota: la función fct_infreq() no está ordenando en este caso las columnas (se desconoce la razón). El ordenamiento aún puede conseguirse si se realiza primero el cálculo del promedio y luego se grafica la columna correspondiete, como en el siguiente bloque de código.
# Cálculo del promedio de esperanza de vida por continente
gapminder_mean_lifeExp_continent <-
gapminder |>
filter(year == 2007) |>
group_by(continent) |>
summarize(lifeExp_mean = mean(lifeExp))
# Despliegue por orden descendente del promedio de esperanza de vida
gapminder_mean_lifeExp_continent |>
arrange(desc(lifeExp_mean))# A tibble: 5 × 2
continent lifeExp_mean
<fct> <dbl>
1 Oceania 80.7
2 Europe 77.6
3 Americas 73.6
4 Asia 70.7
5 Africa 54.8Luego se dibuja luego el gráfico con geom_col() y se ordenan las barras con reorder().
# Gráfico de barras con promedio de esperanza de vida
# para cada continente para el año 2007
grafico_barras_ggplot2 <-
gapminder_mean_lifeExp_continent |>
ggplot(aes(x = reorder(continent,-lifeExp_mean), y = lifeExp_mean)) +
geom_col(aes(
text = paste0(
"Continente: ",
continent,
"\n",
"Promedio de esperanza de vida: ",
lifeExp_mean
)
)) +
ggtitle("Promedio de esperanza de vida por continente en 2007") +
xlab("Continente") +
ylab("Promedio") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2, tooltip = "text") |>
config(locale = 'es')El uso de geom_col() se ampliará en la sección siguiente.
9.6.3.2 Barras sin transformaciones estadísticas
En algunos conjuntos de datos, el valor que se quiere representar en la longitud de las barras ya está presente como una variable en el conjunto de datos, por lo que no es necesario que ggplot2 realice una transformación estadística. En estos casos, se utiliza la función geom_col().
Nota: para dibujar barras sin transformaciones estadísticas, tambien es posible utilizar la función geom_bar(). En este caso, al argumento stat se le asigna el valor "identity" y al argumento y de aes() la variable que contiene el valor que quiere mostrarse en las barras.
El siguiente gráfico de barras muestra la población de los países de los países de América en 2007. Nótese que este valor se puede tomar directamente de la variable pop, después de realizar los filtros correspondientes.
# Gráfico de barras con población de países
# de América para el año 2007
grafico_barras_ggplot2 <-
gapminder |>
filter(year == 2007 & continent == "Americas") |>
ggplot(aes(x = reorder(country, pop), y = pop/1000000)) +
geom_col(aes(text = paste0(
"País: ",
country,
"\n",
"Población (millones de habitantes): ",
pop/1000000
))) +
coord_flip() + # para mostrar barras horizontales
ggtitle("Población de países de América en 2007") +
xlab("País") +
ylab("Población (millones de habitantes)") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2, tooltip = "text") |>
config(locale = 'es')9.6.3.3 Barras apiladas
Al usar el argumento fill de aes(), las barras de un gráfico pueden dividirse de acuerdo con una variable adicional, produciendo el efecto de barras apiladas (i.e. unas sobre otras).
En el siguiente bloque de código, se genera un gráfico de barras apiladas que, para el conjunto de datos diamonds, muestra las cantidades de diamantes por corte (cut) subdivididas por claridad (clarity).
# Gráfico de barras apiladas por tipo de corte y claridad
grafico_barras_ggplot2 <-
diamonds |>
ggplot(aes(x = cut, fill = clarity)) +
geom_bar() +
ggtitle("Cantidad de diamantes por corte y claridad") +
xlab("Corte") +
ylab("Cantidad") +
labs(fill = "Claridad") +
theme_minimal()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')El argumento position = "fill" de geom_bar() también genera barras apiladas, pero le asigna a todas las barras la misma longitud, facilitando así la comparación de proporciones.
# Gráfico de barras apiladas por tipo de corte y claridad
grafico_barras_ggplot2 <-
diamonds |>
ggplot(aes(x = cut, fill = clarity)) +
geom_bar(position = "fill") +
ggtitle("Proporción de tipos de claridad en cortes de diamantes") +
xlab("Corte") +
ylab("Proporción") +
labs(fill = "Claridad") +
theme_minimal()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')9.6.3.4 Barras agrupadas
El argumento position = "dodge" de geom_bar() genera barras agrupadas (i.e. unas al lado de otras), facilitando así la comparación de valores individuales.
# Gráfico de barras agrupadas por tipo de corte y claridad
grafico_barras_ggplot2 <-
diamonds |>
ggplot(aes(x = cut, fill = clarity)) +
geom_bar(position = "dodge") +
ggtitle("Cantidad de diamantes por corte y claridad") +
xlab("Corte") +
ylab("Cantidad") +
labs(fill = "Claridad") +
theme_minimal()
# Gráfico de barras plotly
ggplotly(grafico_barras_ggplot2) |>
config(locale = 'es')9.6.4 Gráficos de dispersión
Un gráfico de dispersión (scatterplot) despliega los valores de dos variables numéricas, como puntos en un sistema de coordenadas. El valor de una variable se despliega en el eje X y el de la otra variable en el eje Y. Variables adicionales pueden ser mostradas mediante atributos de los puntos, tales como su tamaño, color o forma.
En ggplot2, los gráficos de dispersión se implementan con la función de geometría geom_point().
El siguiente bloque de código muestra la relación entre el PIB per cápita y la esperanza de vida de los países en el conjunto de datos gapminder, para el año 2007.
# Gráfico de dispersión PIB per cápita vs esperanza de vida en 2007
# + línea de tendencia
grafico_dispersion_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap, y = lifeExp)) +
geom_point(aes(
text = paste0(
"País: ",
country,
"\n",
"PIB per cápita: ",
gdpPercap,
"\n",
"Esperanza de vida: ",
lifeExp
)
)) +
geom_smooth(method = "lm") +
ggtitle("PIB per cápita vs esperanza de vida en 2007") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Esperanza de vida (años)") +
labs(caption = "Fuente: Gapminder.org") +
theme_economist()
# Gráfico de dispersión plotly
ggplotly(grafico_dispersion_ggplot2, tooltip = "text") |>
config(locale = 'es')Como se explicó anteriormente, se pueden agregar al gráfico variables adicionales mediante su mapeo a propiedades visuales. En el siguiente ejemplo, se agrega la variable de continente al gráfico anterior, mediante su mapeo a la propiedad correspondiente al color.
# Gráfico de dispersión PIB per cápita vs esperanza de vida por continente en 2007
grafico_dispersion_ggplot2 <-
gapminder |>
filter(year == 2007) |>
ggplot(aes(x = gdpPercap, y = lifeExp, color = continent)) +
geom_point(aes(
text = paste0(
"País: ",
country,
"\n",
"Continente: ",
continent,
"\n",
"PIB per cápita: ",
gdpPercap,
"\n",
"Esperanza de vida: ",
lifeExp
)
)) +
ggtitle("PIB per cápita vs esperanza de vida por continente en 2007") +
xlab("PIB per cápita ($ EE.UU.)") +
ylab("Esperanza de vida (años)") +
labs(caption = "Fuente: Gapminder.org", color = "Continente") +
theme_economist()
# Gráfico de dispersión plotly
ggplotly(grafico_dispersion_ggplot2, tooltip = "text") |>
config(locale = 'es')9.6.5 Gráficos de líneas
Un gráfico de líneas muestra información en la forma de puntos de datos, llamados marcadores (markers), conectados por segmentos de líneas rectas. Es similar a un gráfico de dispersión pero, además del uso de segmentos de línea, tiene la particularidad de que los datos están ordenados, usualmente con respecto al eje X. Los gráficos de línea son usados frecuentemente para mostrar tendencias a través del tiempo.
En ggplot2, los gráficos de líneas se implementan con la función de geometría geom_line().
El siguiente gráfico de línea muestran la evolución en el tiempo de los casos positivos, fallecidos, recuperados y activos de COVID-19 en Costa Rica.
# Gráfico de líneas con la evolución de los casos de COVID
grafico_lineas_ggplot2 <-
covid_general |>
ggplot(aes(x = fecha, y = value, color = variable)) +
geom_line(aes(y = positivos, color = "Positivos")) +
geom_line(aes(y = recuperados, color = "Recuperados")) +
geom_line(aes(y = activos, color = "Activos")) +
geom_line(aes(y = fallecidos, color = "Fallecidos")) +
scale_color_manual( # colores
"",
values = c(
"Positivos" = "blue",
"Recuperados" = "green",
"Activos" = "red",
"Fallecidos" = "black"
)
) +
ggtitle("Casos acumulados de COVID en Costa Rica al 2022-05-30") +
xlab("Fecha") +
ylab("Casos") +
theme_economist()
# Gráfico de dispersión plotly
ggplotly(grafico_lineas_ggplot2) |>
config(locale = 'es')9.6.6 Otros tipos de gráficos
ggplot2 provee más de 40 tipos de geometrías para gráficos (puntos, líneas, barras, histogramas, cajas, etc.) y los paquetes de extensión proporcionan aún más (ej. https://exts.ggplot2.tidyverse.org/gallery/).
Para una explicación resumida de ggplot2, se recomienda leer Data visualization with ggplot2::Cheat Sheet.
9.7 Recursos de interés
DT: An R interface to the DataTables library. (s. f.). Recuperado 21 de mayo de 2022, de https://rstudio.github.io/DT/
Healy, Y. H. and C. (s. f.). From data to Viz | Find the graphic you need. Recuperado 20 de marzo de 2022, de https://www.data-to-viz.com/
RStudio. (2017). Data visualization with ggplot2::Cheat Sheet. https://raw.githubusercontent.com/rstudio/cheatsheets/main/data-visualization.pdf
Wickham, H. (2010). A Layered Grammar of Graphics. Journal of Computational and Graphical Statistics, 19(1), 3-28. https://doi.org/10.1198/jcgs.2009.07098